- Svenska
-
EnglishDeutschItaliaFrançais한국의русскийSvenskaNederlandespañolPortuguêspolski繁体中文SuomiGaeilgeSlovenskáSlovenijaČeštinaMelayuMagyarországHrvatskaDanskromânescIndonesiaΕλλάδαБългарски езикGalegolietuviųMaoriRepublika e ShqipërisëالعربيةአማርኛAzərbaycanEesti VabariikEuskeraБеларусьLëtzebuergeschAyitiAfrikaansBosnaíslenskaCambodiaမြန်မာМонголулсМакедонскиmalaɡasʲພາສາລາວKurdîსაქართველოIsiXhosaفارسیisiZuluPilipinoසිංහලTürk diliTiếng ViệtहिंदीТоҷикӣاردوภาษาไทยO'zbekKongeriketবাংলা ভাষারChicheŵaSamoa日本語SesothoCрпскиKiswahiliУкраїнаनेपालीעִבְרִיתپښتوКыргыз тилиҚазақшаCatalàCorsaLatviešuHausaગુજરાતીಕನ್ನಡkannaḍaमराठी
Hur IoT-enheter fungerar: Arkitektur, komponenter och prestandafaktorer
Katalog
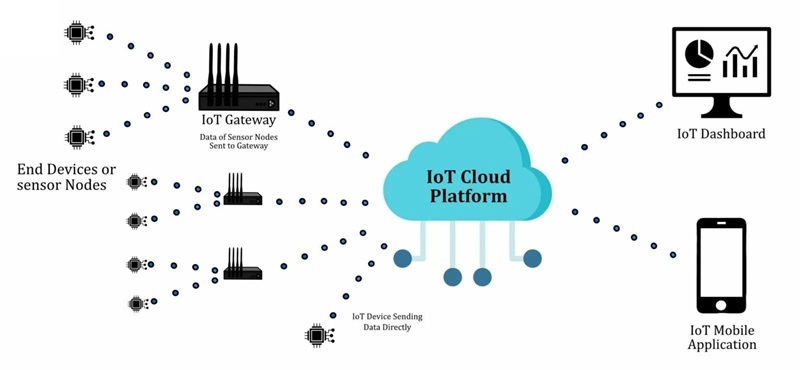
Hur en IoT-enhet fungerar
En IoT-produkt är lättare att resonera kring när den behandlas som en sluten, mätbar slinga: den observerar den fysiska världen, konverterar det den observerat till data som elektroniken kan hantera, flyttar dessa data till en plats där de kan tolkas, och utlöser sedan ett svar. Många team börjar med att jaga "uppkoppling", och det är förståeligt, demonstrationer ser fantastiska ut när instrumentpanelen uppdateras i realtid, men i fältet bedöms enheten efter om den beter sig på samma sätt dag 3, dag 30, och dag 300.
Slingan måste klara av vardagliga begränsningar som tenderar att dyka upp vid de värsta tillfällena: begränsad kraft, oförutsägbar latens, störningar, kostnadstak och utvecklande säkerhetsförväntningar. När slingans konstruktion tar dessa begränsningar i beaktande, känns nätverks- och molnlager som en ren förlängning av produkten istället för en källa till överraskningar och ömtåliga edge-fall.
Mäta: Att omvandla en fysisk signal till en elektrisk signal
Vid kanten konverterar en sensor en verklig variabel till en elektrisk representation som enheten kan mäta. Variabeln kan vara miljömässig, mekanisk eller elektrisk, och sensorens uppgift är att skapa en signal som förblir tolkbar över temperaturvariationer, vibrationer och installationsvariationer.
Vanligt förekommande verkliga variabler som mäts:
• Temperatur
• Vibration
• Tryck
• Ljus
• Rörelse
• Ström
• Gaskoncentration
Sensorutsignalen hamnar typiskt i en av två kategorier, och valet påverkar allt nedströms (front-end-design, sampling och brusacceptans).
Vanliga sensortyper:
• Analog: en kontinuerligt varierande spänning eller ström
• Digital: paketerade mätningar över I²C/SPI/UART
Utanför laboratorieförhållanden beror mätprecisionen på mer än sensorn själv. Installationsfaktorer såsom placering, monteringskraft, luftflöde, närliggande värmekällor, kabeldragning och mekanisk koppling kan påverka resultaten avsevärt.
Mätfel orsakas ofta av installationsproblem snarare än sensorfel. Flexibla monteringsytor eller resonansstrukturer kan förvränga data och skapa missvisande avläsningar. Att behandla montering och mekanisk design som en del av mätSystemet hjälper till att minska felsöknings tiden och förbättrar mätningens tillförlitlighet.
Behandla: Analog front end (AFE) och signalhygien
Många enheter dirigerar rå sensorutsignaler genom en analog front end (AFE) före digitalisering. Detta steg formar tyst huruvida resten av systemet arbetar med en stabil, pålitlig signal eller med något som endast beter sig under kontrollerade förhållanden.
Typiska AFE-funktioner:
• Biasing och referensgenerering för att hålla signaler inom ADC:ns giltiga ingångsområde
• Förstärkning (instrumentationsförstärkare, förstärkningssteg) för att göra små signaler mätbara
• Filtrering (lågfrekvens, anti-alias filtrering) för att minska brus och begränsa vilseledande högfrekvent innehåll
• Skydd (ESD-strukturer, överspänningsskydd, ingångsklämmor) för att överleva kabelfel och hantering
Verkliga driftsmiljöer introducerar ofta bruskällor såsom motorer, långa kablar, switchande regulatorer och närliggande radioapparater. Dessa effekter kan skapa mätfel som verkar slumpmässiga tills källan identifieras.
God jordning, korrekt avskärmning och grundläggande anti-alias filtrering förbättrar ofta signalens kvalitet mer effektivt än att enbart förlita sig på komplex programvarufiltrering. Att hantera brus vid källan ger vanligtvis mer tillförlitliga mätningar och systemprestanda.
Konvertera: ADC-provtagning med avsiktliga avvägningar
När signalen är analog, konverterar en ADC den till digitala prover. Själva konverteringen är okomplicerad; det som ofta kräver erfarenhet är att välja provtagningsparametrar som fungerar bra under riktiga batteri- och nätverksbegränsningar.
Två provtagningsval som formar beteendet nedströms:
• Provtagningstakt: tillräckligt snabb för att fånga fenomenet, men inte så snabb att den drar ström och producerar onödiga data
• Upplösning: tillräckligt fin för att upptäcka meningsfulla förändringar utan att omvandla brus och drifter till falsk precision
Provtagning fungerar bäst när det behandlas som ett systembeslut istället för en isolerad specifikation. Överprovtagning kan tyst tvinga mer radioaktivitet (och radiotid är ofta det som tömmer batteriet först). Underprovtagning kan missa korta, operativt meningsfulla händelser, trycktoppar, stötar, kortvariga avbrott, som användare kommer ihåg för att de var ögonblicken då något gick fel.
Beräkna: Mikrokontrollerbearbetning, tidtagning och kantlogik
En mikrokontroller (MCU) läser vanligtvis sensordata enligt ett disciplinerad schema med hjälp av timrar, avbrott och DMA så att enhetens tidtagning förblir konsekvent även när programvaran växer. Konsekvent tidtagning är en av de detaljer som känns tråkiga tills den dag du felsöker ett fältproblem och inser att "signalen" faktiskt var schemaläggningsjitter.
Vanliga bearbetningsuppgifter på MCU-sidan:
• Digital filtrering (glidande medelvärde, median, IIR) för att minska jitter och avvikelser
• Kalibrering och kompensation (offsetkorrigering, temperaturkompensation, linjarisering)
• Regelutvärdering (trösklar, hysteresis, debouncing) för att förhindra instabil växling
• Lättviktig kantanalys (funktionsutvinning, anomalisk scoring, kompression) för att minska bandbredd och molnberäkning
En användbar designansats är att separera mätdata från beslutslogik. Sensoravläsningar kan fluktuera på grund av normala fysiska förhållanden, medan stabil systembeteende kan upprätthållas genom hysteresis, tidsfönster och tillståndsmaskinkontroll. Denna separation hjälper till att minska falska larm, förbättrar systemstabilitet och förhindrar felaktiga felindikeringar när temporära mätvariationer inträffar.
Inte varje beslut gynnas av att vänta på molnet. Vissa åtgärder är tidskänsliga eller inriktade på att undvika skador, och att skjuta upp dem utanför enheten tenderar att skapa oönskade felmodeller när nätverket är långsamt eller frånvarande.
Exempel som vanligtvis hanteras lokalt:
• Överströmavstängning; överhettningsskydd; motorstilleståndsdetektering
Molnet tenderar att lysa när uppgiften drar nytta av bredare kontext eller längre tidsramar.
Beslutskategorier på molnsidan:
• Långsiktig trendanalys och prediktivt underhåll
• Korsenhetskorrelation
• Modelluppdateringar och policyändringar för hela flottan
En praktisk regel som team ofta enas om är enkel: om en fördröjd åtgärd rimligen skulle kunna leda till skada, bör enheten skydda sig själv först och rapportera efteråt. Denna strategi känns vanligtvis konservativ på ett bra sätt, särskilt när du är den som står till tjänst under en nätverksavbrott.
Kommunicera: Radio-/trådbundna länkar och applikationsprotokoll
Kommunikationslagret flyttar telemetri till en telefon, gateway eller molnslutpunkt. Att välja en länksteknik handlar mindre om vad som är trendigt och mer om vad som passar den fysiska miljön, distributionsmodellen och effektbudgeten.
Vanliga anslutningsalternativ:
• Wi-Fi; BLE; Zigbee/Thread; mobil (LTE-M/NB-IoT); Ethernet
Ovanför länk lagret använder enheter applikationsprotokoll för att strukturera och leverera meddelanden. Rätt protokoll beror ofta på om produkten behöver strömmande telemetri, konfigurationsarbetsflöden eller kompatibilitet med befintlig företagsinfrastruktur.
Vanliga applikationsprotokoll:
• MQTT
• HTTP
Verkliga distribuerade system erbjuder sällan stabil samband. Åtkomstpunkter startar om, gatewayar försvinner, mobil täckning förändras och störningar kommer och går. Enheter känns mycket mer pålitliga när de kan buffra data, försöka igen med återhållsamhet (inte på ett sätt som DDOS:ar nätverket), och bibehålla ett tydligt sist kända tillståndsbeteende så att systemet förblir förståeligt när länkarna är imperfekta.
Telemetri skyddas vanligtvis med TLS för konfidentialitet och integritet. I många produkter är den första säkerhetsvinsten helt enkelt att få kryptering aktiverad överallt, men varaktig säkerhet går längre genom att göra identitet och uppdateringar hanterbara under hela enhetens livscykel.
Vanliga säkerhetsbyggblock:
• Unika enhetsidentiteter och certifikatbaserad autentisering
• Säker nyckellagring (säkra element eller MCU-trustzoner)
• Signerad firmware och säker start för att minska risken för obehörig kodexekvering
Det finns ett mönster som erfarna team känner igen (ofta efter att ha lärt sig på den svåra vägen): säkerhetsarbete är mycket mindre plågsamt när identitet, nyckelhantering och uppdateringsvägar designas tidigt. När dessa grunder planeras från början tenderar enheten att förbli servicetärd i år, inte bara tills den första stora fältuppdateringen.
Moln och Data
I molnet (eller på en lokal plattform) lagras data, ofta i tidsseriersystem, och aggregateras och analyseras sedan. Molnet är där rå telemetri kan omvandlas till utdata som någon faktiskt kommer att agera på, oavsett om den någon är en användare, en operatör eller en automatisk policy-motor.
Vanliga molnutdata:
• Varningar (tröskelöverskridanden, felupptäckter)
• Förutsägelser (återstående användbar livslängd, avdriftupptäckter)
• Instrumentpaneler (KPI:er, trender, flotta/enhetshälsa)
• Kontrollkommandon (inställningspunkter, scheman, aktivera/avaktivera åtgärder)
Molnets värde är lättast att fånga när teamen bestämmer i förväg vilka beslut data ska stödja. Utan den disciplinen tenderar telemetri att bli dyr bakgrundsbrus, insamlad pålitligt, lagrad pliktskyldigt, och sedan sällan använd med självförtroende.
Aktuera: Utföra Kommandon Säkert och Återkommande
Kommandon som skickas tillbaka till enheten driver aktuatorer, och denna del av loopen är där hårdvarurealiteten blir ljudlig. Aktivering kräver drivkretsar anpassade till lasten, och det gynnas av skyddsräcken som gör fel förutsägbara snarare än kaotiska.
Vanliga aktuatorer:
• Motorer
• Ventiler
• Reläer
• Värmare
• LED-lampor
• Högtalare
Vanliga driv- och skyddselement:
• MOSFET:er; reläer; H-bryggor; triacs (beroende på lastens egenskaper)
• Flyback-dioder och snubber (för induktiva laster)
• Strömavkänning och termiska skydd
• Tillståndsverifiering när det är tillgängligt (gränssnittsbrytare, positionsfeedback, elektriska signaturer)
En pålitlig inställning som tenderar att löna sig är att anta att aktivering är där risken koncentreras. Sensorer misslyckas ofta tyst; aktuatorer kan misslyckas på sätt som användare genast märker. Enkla säkerhetsåtgärder, tidsgränser, lås, och sanity-kontroller förhindrar ofta kaskadproblem och gör systemet mer pålitligt under de oundvikliga märkliga randfallen.
Loopen Upprepas
Denna känsla; databehandling, kommunikation, aktivering cykeln upprepas kontinuerligt. Lokalt kan den köras på millisekunder; en molnretur kan ta sekunder beroende på nätverket och belastningen på backend. Bra produkter behandlar tid och kraft som designingångar som formar alla andra beslut, snarare än som eftertankar som ska optimeras i slutet.
Vanliga systemnivåstrategier:
• Använd kantbearbetning för att minska onödiga överföringar
• Batcha och komprimera telemetri när latens-tolerans tillåter det
• Sova aggressivt och väcka förutsägbart på batteridrivna enheter
• Bibehålla "minimalt livskraftigt beteende" även när molnet inte kan nås
En hållbar IoT-enhet definieras inte av någon enskild komponent. Den definieras av hur lugnt hela loopen beter sig när verkligheten avviker från planen: bullriga signaler, oregelbundna nätverk, åldrande hårdvara och oförutsägbart användarbeteende. Att designa med dessa förhållanden i åtanke är ofta skillnaden mellan en demo som fungerar en gång och en produkt som behåller sitt lugn år efter år.
Elektroniska Komponenter på IoT Enhets Prestanda
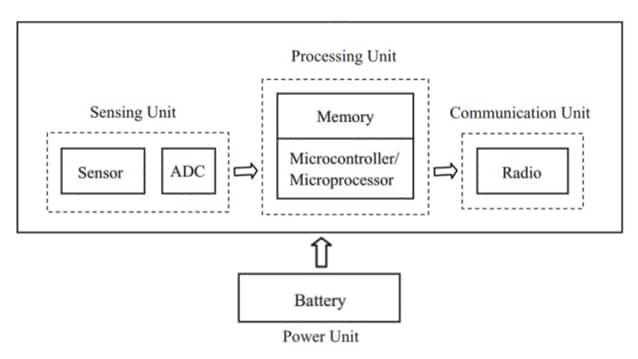
IoT-hårdvara tenderar att kännas pålitlig endast när sensorinmatningar, beräkning, lagring, kraftleverans och anslutning formas som en enda kontinuerlig signal- och kraftväg.
En sensoravläsning förblir sällan meningsfull om referensspänningen skiftar, om klockan jitter, eller om datapathen ibland tappar bytes under belastning. En radiolänk förblir sällan användbar om strömförsörjningen faller under sändningspulsar, om oscillatorn är brusig, eller om hantering av referenser är inkonsekvent över återställningar.
Många team lär sig att tillförlitlighet ofta förbättras mer av att strama åt gränserna block till block än av att lägga till en ny funktion: förutsägbara spår, avgränsad timing, kontrollerad bruskoppling och felbeteende som är förståeligt när något går sönder.
Designmålet är inte "perfekta delar", utan gränssnitt som beter sig på samma sätt på en utvecklarbänk, i pilotutdelningar och månader senare i fältet.
Sensor
Sensore generar verkliga förhållanden till elektriska signaler, men produktens beteende från dag till dag formas av detaljer som kan se små ut tills fältdatadata gör att de känns obekvämt stora.
Brus, drift, montering, luftflöde, kondensation och kabeldragning har alla en tendens att förvandla en ren labplot till röriga fördelningar som firmware måste överleva.
Räckvidd och upplösning behöver passa det beslut som fattas, inte en rubrikspecifikation. Överdrivet känsliga konfigurationer förstärker ofta brus och drift, vilket tenderar att öka falska positiva och tyst ökar beräkningstiden och radio luften. En så begränsad räckvidd som möjligt kan se försvarbar ut under designgranskningar, men fältbeteende föredrar ofta en något bredare räckvidd som ger jämnare, mer tolkningsbara mätningar. Om en nedströmsmodell eller tröskel för att släta ut datan ändå ska smidiga, kan det kännas tillfredsställande att trycka rå känslighet för långt till en början och sedan frustrerande när supportärenden kommer in.
Drift, åldrande och exponering avgör om mätningar förblir trovärdiga efter månader eller år.
Kalibrering fungerar generellt bättre när den behandlas som en livscykelrutin snarare än en enstaka fabriksritual som alla hoppas kommer att hålla för evigt.
• Fabriks kalibrering med lagrade koefficienter.
• Återkalibreringsutlösare i fält (schemalagda, händelsebaserade eller tekniker-assisterade).
• Självkontrollrutiner som flaggar avvikelser, klippning och mättnad.
Team som siktar på tjänstbara produkter avsätter ofta blygsam flash och beräkningar för kalibreringsmetadata, spårbarhet och sanity checks, eftersom det är billigare än att förklara inkonsekventa avläsningar efter distribution.
Urvals av sampelfrekvens blir vanligtvis en förhandling mellan fysik, batteri och datanytta. Att sampelera för långsamt riskerar aliasing och missade händelser, vilket kan vara svårt att diagnostisera eftersom datan fortfarande verkar plausibel. Att sampelera för snabbt ökar effektförbrukning och datavolym, och det kan skapa illusionen av bättre insikter utan att materiellt förbättra beslut.
Ett mönster som håller bra är att fånga fenomenet med tillräcklig marginal, filtrera tidigt (analogt när det verkligen hjälper, digitalt när det är tillräckligt) och nedprova för rapportering.
Detta ger ofta bättre batteriresultat än att sampelera aggressivt och hoppas på att molnanalys ska kompensera senare.
Huruvida en extern ADC är berättigad beror vanligtvis på upplösning, ingångsimpedans, referensstabilitet och brusnivå. MCU-integrerade ADC:er presterar ofta bra för medelupplösningssensorer, medan precisionstecken tenderar att straffa en avslappnad layout och referensval.
• Val av lågbrusreferens och referensdragning.
• Jordningsstrategi, skyddsspår och återvändsvägsstyrning.
• Skärmning och avsiktlig kabeldragning nära kontakter.
• ESD-skydd placerat där det faktiskt fångar transienten.
Små PCB-förändringar kan mätbart minska jitter och förbättra upprepbarhet, särskilt för högimpedanta källor eller lågnivå analogsignaler där "nästan bra" blir tydligt instabilt i produktionsdata.
Mikrokontroller (MCU)
MCU: n fungerar som det operativa centret: den läser sensorer via GPIO, I²C, SPI och UART; bearbetar signaler; kör inferenser där det är tillämpligt; hanterar strömlägen; och driver utgångar.
När MCU-beteendet är förutsägbart känns hela enheten lugn; när det inte är det, tenderar fel att se slumpmässiga ut även när orsaken är deterministisk.
Stabil firmware kommer vanligtvis från explicita tillståndsmaskiner och timing som har klara gränser. Händelsedrivna designer som använder avbrott, DMA och tidtagare överträffar vanligtvis polling-loopar i respons och energi, särskilt i enheter som ofta sover.
När team beskriver slumpmässiga låsningar är orsaken ofta en av ett par återkommande syndare: obundna arbeten inuti ett avbrott, dödläge på delad buss, prioriteringsinversion eller minnesfragmentering som aldrig blev stress-testad under långa driftsamma perioder.
Planering av RAM och flash fungerar bättre när det inkluderar vad som händer efter att den första demon har lyckats.
• Nätverksbuffertar och TLS-överhead (inklusive värsta fall av handske-beteende).
• Logging, metriska och kraschen dump som ingenjörer kommer att be om senare.
• OTA staging utrymme, plus metadata för integritetskontroller.
• Funktionalitetskrav som förutsägbart dyker upp efter pilotfeedback.
Undermålig minneskapacitet är ofta tyst i början och blir sedan smärtsam senare, just när diagnostik och uppdateringssäkerhet blir de främsta verktygen för att kontrollera fältets risk.
Enheter som förväntas vara betrodda drar vanligtvis nytta av säker boot, skyddad nyckellagring, hårdvaru-kryptoacceleration och en verklig slumptalsgenerator. Från deployments erfarenhet tenderar säkerhetsåtgärder att kännas obekväma eftersom de krockar med skickad hårdvaru begränsningar och långlivade autentiseringar.
Att välja en MCU (eller lägga till ett säkert element) som stöder stark identitet och mätt boot minskar ofta mängden smart mjukvara som behövs för att kompensera för svaga förtroenden.
Åtkomst för SWD/JTAG och praktisk testbarhet avgör vanligtvis huruvida tidig tillverkning är kontrollerad eller kaotisk.
• SWD/JTAG åtkomstplanering och låsstrategi för produktion.
• Testpunkter och provvänlig layout för högvolym verktyg.
• Kraftledningssensingpunkter och mätbara noder för snabb triage.
En liten mängd testinfrastruktur kan spara team veckor av obekväma gissningar när det första stora partiet avslöjar hörnfall som aldrig visade sig på handbyggda prototyper.
Kommunikationsmoduler
Kommunikationsmodulen formar mer än länkbudget: den påverkar provisioning, uppförande under uppdateringar, supportarbejdsflöden och ett förvånande antal feltyper.
I batterienheter dominerar radios beteende ofta energiförbrukningen, så anslutningsbeslut tenderar att bli batteritidsbeslut i förklädnad.
Urvalet balanserar vanligtvis räckvidd, latens, genomströmning, topologi och kraftbudget, med en frank blick på operationell friktion.
• BLE för kort räckvidd, låg effekt och smartphone-kommisionering.
• Wi‑Fi för högre genomströmning med högre toppström och strängare krav på effektintegritet.
• Thread/Zigbee för mesh-nätverk och låg effekt hem-/industriella implementationer.
• LoRaWAN för lång räckvidd, låga datahastigheter och sträng payload-disciplin.
• LTE‑M/NB‑IoT för bredområdes täckning med operatörsbegränsningar och mer komplex provisioning.
Team känner ofta lättnad när de erkänner att "radio val" är oskiljaktigt från firmware återförsöksstrategi, toppströmsbehandling och användarens tålamod under installationen.
En stark modul kan fortfarande besvikelse om antennen är dåligt placerad, urtuningad av omslaget, eller utsatt för bullriga jordreturer.
• Antennas håll-zonering och kontrollerad impedans-routing.
• Omslagseffekter och användar-interaktionstester.
• Utsända emissionskontroller och känslighetstestning.
När länkmarginalen är tunn kan firmware-återförsök dölja symptomen en stund, men batterikostnaden ackumuleras på ett sätt som driftsteam märker långt före ingenjörer ser det i ett labb.
Anslutningsdesign måste överleva verkliga arbetsflöden snarare än ideala demoer.
• Provisioning som tolererar partiella fel och vanliga användarfel.
• Återkoppling och återförsökslogik som undviker självförorsakade batteriläckager.
• Roamingbeteende plus SIM/eSIM livscykelhantering för mobila enheter.
• OTA med autentisering, rollback och bandbredd-medveten schemaläggning.
OTA fungerar mindre som en blänkande funktion och mer som en långsiktig underhållskanal; när den behandlas nonchalant tenderar enheter att bli dyra att stödja, även om den första lanseringen ser bra ut.
Energihantering
Kraftdesign håller enheten levande, upprepbar och tråkig, i bästa bemärkelse. Den spänner över regulatorer, laddning, bränslekontroller, lastomswitching och skyddsalternativ som måste hantera både toppströms händelser och djupsömnförväntningar.
Buck/boost/LDO-val drar nytta av att evaluera effektivitet över hela lastintervallet, inte bara en enda arbetspunkt. I viloläge blir den inaktiva strömmen ofta avgörande för huruvida en produkt uppfyller batteriets förväntningar.
Radion kan skapa skarpa strömspikar; bulk kapacitans, låg impedansrouting och stabila kontroll-loopar tenderar att avgöra om systemet förblir aktivt under överföringsutbrott. Många mystiska återställningar kan spåras tillbaka till transienta droppar snarare än firmware, vilket kan vara en ödmjukande men användbar läxa under integration.
Batterilivslängden vinns ofta under sömn, där små läckor ackumuleras till mätbara förluster.
• Djup sömn konfiguration med endast de väckningskällor som verkligen används.
• RTC eller låg effekt timers för periodiska väckningar.
• GPIO eller sensorinterrupts för händelsedrivna väckningar.
• Kraftavstängning för sensorer och perifera enheter som inte behöver kontinuerlig bias.
Att mäta sömnen tidigt på riktig hårdvara, och sedan behandla oväntade mikroamp ökningarna som buggar, tenderar att förhindra den långsamma krypningen där många "nästan avstängda" block tyst eroderar driftstiden.
Valet av laddnings-IC beror på kemi, termiska begränsningar, reglerande krav och den förväntade miljön. Valet av bränslemätare bör återspegla noggrannhetsbehov över temperatur, belastning och åldrande. För utomhus- eller ouppvärmda installationer blir beteende vid låga temperaturer ofta drivkraften för upplevd kvalitet, så konservativa spänningsgränser och ärlig kapacitetsrapportering minskar klagomål om plötsliga avstängningar.
Överström, överspänning, omvänd polaritet och ESD-beteende bör behandlas som rutinmässiga driftförhållanden för många installationer. Industrimiljöer producerar vanligtvis kabelurladdningsevenemang och induktiva transienta som kan se ut som "dålig tur" om inte designen förutser dem. Lämpliga klämmor, säkringar, TVS-dioder, inrush-kontroll och isoleringsbeslut avgör ofta om en enhet överlever sin första månad med ett intakt rykte.
Lagringskomponenter
Lagring håller firmware, konfiguration, certifikat och loggar. Valet mellan NOR/NAND flash, EEPROM, FRAM, eMMC eller microSD drivs ofta av hållbarhet, prestanda, BOM-kostnad och hur smärtsam en korrupt skrivning skulle vara operationellt.
Riktiga enheter står inför bruna utbrott, watchdog-återställningar och partiella skrivningar.
• Kontrollsummor eller CRC för konfiguration och loggar.
• Slitsnivellering eller begränsad skrivfrekvens för flash-baserade medier.
• Journalföring eller endast tilläggsregister för data som inte kan halvsprutas.
Ett vanligt operationellt mönster är ringbuffertloggning med begränsade skrivhastigheter, vilket begränsar tyst uthållighetsförbrukning samtidigt som det fortfarande lämnar tillräckligt med brödsmulor för att felsöka fältproblem.
A/B-firmwareplatser plus verifierad uppstart och återställningslogik ger ett praktiskt skyddsnät under avbrutna uppdateringar. Utan dessa säkerhetsåtgärder kan en enda strömförlust under en uppdatering stranda enheter i fältet. Produkter som skalar smidigt tenderar att behandla återhämtningsförmåga på samma nivå som fraktfunktioner, eftersom supportkostnader tenderar att följa kvaliteten på återhämtningsberättelsen.
Certifikat och nycklar bör lagras med tanke på motståndskraft mot manipulering och åtkomstkontroll, inte bara någonstans icke-flyktig. Även med säker lagring minskar planer för nyckelrotation, återkallelse och incidentrespons långvarig exponering när en referensuppgift läcker eller en flotta delvis är komprometterad.
Gränssnittskomponenter
LED-lampor, skärmar, knappar, mikrofoner, kameror och biometriska sensorer formar användbarheten, men de drar också in kraft, EMI-risk och integritetsöverväganden. En UI som känns konsekvent under stress återspeglar ofta disciplinerad elektrisk design mer än UI-polering.
Knappar tenderar att behöva debouncing och ESD-skydd för att undvika sporadiska felaktiga avläsningar.
Mikrofoner och kameror tenderar att behöva rena spänningar och noggrann jordning för att undvika intermittenta artefakter som användare tolkar som "flakiga."
• Separation av känsliga analoga vägar från höga strömvägar och RF-vägar.
• Återföringsvägsplanering för att begränsa bruskoppling.
• Avskärmning och filtreringsval som matchar höljet och kabelstrategin.
Intermittenta UI-fel orsakas ofta av koppling från radios eller motorer, och det kan vara överraskande tillfredsställande att åtgärda dem med layout och jordningsdisciplin snarare än ändlösa firmware-lösningar.
Enheter beter sig mer förutsägbart när de har en offline-berättelse som inte är beroende av att nätverket är tillgängligt.
Tydlig lokal återkoppling (entydiga LED-statusar och minimal, noggrann felindikering) tenderar att minska supportbelastningen och undvika den frustration som användare känner av tyst felbeteende.
Aktuatorer
Aktuatorer omvandlar kontrollintention till rörelse, värme eller kraft, och de kräver vanligtvis gränssnittskretsar utöver en direkt MCU-stift. Eftersom aktuatorer interagerar med den fysiska världen tenderar felmod att vara synliga, kostsamma och känslomässigt eskalerande för användare. Motorer, solenoider, ventiler och reläer behöver vanligtvis MOSFET-steg, H-bryggor eller dedikerade drivrutins-IC:er dimensionerade för verkliga strömmar och transienter.
• Flyback-dioder eller snubbers för induktiva belastningar.
• Strömsensorering för stallavkänning och överbelastningsrespons.
• Termiska designöverväganden för kontinuerliga eller högpresterande belastningar.
Fielderfarenhet visar ofta aktuatorrelaterade problem som en frekvent felkälla, och konservativ nedgradering plus felavkänning tenderar att förbättra flottans beteende på ett sätt som supportteam snabbt lägger märke till.
En enhet bör förbli säker när firmware kraschar, molnet är otillgängligt eller kommandon anländer sent.
• Watchdogs och återställningsstrategi anpassade till säkra utgångar.
• Standard-säkra utgångstillstånd definierade per aktuator och per läge.
• Mekaniska fail-safe-positioner där applikationen kräver det.
De mest resilienta designen behandlar förlust av anslutning som ett normalt driftsläge och definierar exakt vad aktuatorn gör under den tiden, så att beteendet förblir förutsägbart även när allt annat är imperfekt.
Systemnivåintegration
Högverkningsfulla förbättringar kommer ofta från integrationsmetoder som tvingar hela systemet att tala sanning tidigt.
• Validering av effektintegritet under sämsta radio- och aktuatorbelastning.
• Bullerkontroll över analog avkänning, växlande regulatorer och högströmdrivare.
• Start-, uppdaterings- och återhämtningsflöden med mätbara tillstånd och tydlig observabilitet.
• Miljötestning (temperatur, fuktighet, vibration) vald för att matcha faktiska installationsförhållanden.
När dessa aktiviteter behandlas som vardagligt ingenjörsarbete snarare än som ceremonier i slutskedet, blir komponentvalen vanligtvis mindre dramatiska, och enhetens beteende tenderar att förbli konsekvent från prototyp till massanvändning.
Slutsats
Framgångsrika IoT-system är beroende av en komplett och pålitlig dataloop som inkluderar avkänning, signalbearbetning, behandling, kommunikation, säkerhet och energihantering. Varje steg påverkar övergripande prestanda, batteritid, noggrannhet och användarupplevelse. Genom att balansera hårdvara, mjukvara, nätverk och operativa begränsningar kan IoT-enheter erbjuda pålitlig övervakning, kontroll och automatisering över ett brett spektrum av tillämpningar.
Vanligt förekommande frågor [FAQ]
1. Varför misslyckas många IoT-projekt på grund av mätkvalitet snarare än anslutningsproblem?
Anslutning får ofta mest uppmärksamhet under utvecklingen eftersom instrumentbrädor och molnintegrationer är mycket synliga. Men felaktiga mätningar orsakade av dålig sensorplacering, vibration, luftflödeseffekter, termisk koppling, brus eller installationsfel kan undergräva hela systemet. Om de ursprungliga uppgifterna är opålitliga kan även de mest avancerade analyser, molnplattformar och kommunikationsnätverk inte producera pålitliga beslut. Långsiktig IoT-framgång börjar vanligtvis med stabila mätningar snarare än sofistikerade anslutningsfunktioner.
2. Varför bör sensorinstallation betraktas som en del av själva avkänningssystemet?
Sensorer mäter fysiska förhållanden genom sin interaktion med den omgivande miljön. Monteringskraft, kabinettdesign, kabelförläggning, luftflöde, vibrationstransferering och termisk kontakt kan alla förändra vad sensorn uppfattar. En perfekt kalibrerad sensor kan fortfarande ge vilseledande avläsningar om den är dåligt monterad. I många installationer bidrar installationsrelaterade fel med mer mätosäkerhet än sensorns specifikationer själva, vilket gör mekanisk integration till en kritisk del av den övergripande avkänningsprestandan.
3. Varför är översampling ofta ett dolt hot mot batteritiden i IoT-enheter?
Att sampla data oftare än nödvändigt ökar bearbetningsbelastningen, minnesanvändningen och kommunikationsaktiviteten. Eftersom trådlös transmission ofta är den största energiförbrukaren i batteridrivna IoT-produkter kan insamling av överdrivna data indirekt öka radioanvändningen och förkorta driftstiden. Även om höga samplingsfrekvenser kan verka förbättra noggrannheten, skapar de ofta större datamängder utan att leverera meningsfulla förbättringar i beslutskvaliteten. Effektiva samplingsstrategier balanserar händelsedetekteringskrav mot energiförbrukning och rapporteringsbehov.
4. Varför separerar framgångsrika IoT-enheter mätlogik från beslutsfattande logik?
Rå sensorvärden fluktuerar naturligt på grund av brus, miljövariation och normalt procesbeteende. Om varje mätning direkt utlöser en åtgärd kan systemen bli instabila och generera falska larm. Genom att separera mätinsamling från beslutlogik med hjälp av hysteresis, tillståndsmaskiner, filtrering, tidsfönster och valideringsregler kan enheter förbli lyhörda samtidigt som onödiga reaktioner på tillfälliga fluktuationer undviks. Denna metod förbättrar tillförlitligheten och skapar mer förutsägbart systembeteende under verkliga förhållanden.
5. Varför behandlas många kritiska IoT-beslut lokalt istället för att delegeras till molnet?
Molnsystem ger värdefull långsiktig analys, flottaförvaltning och prediktiva insikter, men nätverksförseningar och avbrott kan göra dem olämpliga för tidskänsliga skyddsfunktioner. Händelser som överströmsvillkor, överhettning, motorstopp eller säkerhetsavstängningar kräver ofta omedelbar åtgärd. Att vänta på molnbekräftelse kan leda till utrustningsskador eller osäkra förhållanden. Av denna anledning utförs kritiska skyddsoch kontrollbeslut vanligtvis vid kanten medan molnplattformar fokuserar på övervakning och optimering.
Besläktad blogg
-
Hur många nollor i en miljon, miljarder biljoner biljoner biljetter?
![Hur många nollor i en miljon, miljarder biljoner biljoner biljetter?]()
2024/07/29
Miljoner representerar 106, en lätt greppbar siffra jämfört med vardagliga artiklar eller årslöner. Miljarder, motsvarande 109, börjar sträcka ... -
IRLZ44N MOSFET -datablad, krets, motsvarande, pinout
![IRLZ44N MOSFET -datablad, krets, motsvarande, pinout]()
2024/08/28
IRLZ44N är en allmänt använt N-kanals Power MOSFET.Det är känt för sina utmärkta växlingsfunktioner och passar mycket för många applikatione... -
Batteritemperaturen för låg, laddningen stannade.Hur fixar jag det?
![Batteritemperaturen för låg, laddningen stannade.Hur fixar jag det?]()
2024/10/6
Problem med avladdning av batteriladdning av mobiltelefoner är vanliga men kan hanteras effektivt.Temperaturen spelar en stor roll i batterieffektivi... -
BC547 Transistor Comprehensive Guide
![BC547 Transistor Comprehensive Guide]()
2024/07/4
BC547 -transistorn används vanligtvis i en mängd elektroniska applikationer, allt från grundläggande signalförstärkare till komplexa oscillatork... -
En komplett guide till multiplexerare och deras roll i digitala system
![En komplett guide till multiplexerare och deras roll i digitala system]()
2025/09/20
Multiplexerare är komponenter i digitala system, utformade för att kanalisera flera insignaler till en enda utgångslinje med binära logik och styr... -
Omfattande guide till SCR (kiselstyrd likriktare)
![Omfattande guide till SCR (kiselstyrd likriktare)]()
2024/04/22
Kiselstyrda likriktare (SCR) eller tyristorer spelar en viktig roll i kraftelektroniktekniken på grund av deras prestanda och tillförlitlighet.Den h... -
LR621, SR621SW, 364, AG1 -batteriekvivalenter och ersättare
![LR621, SR621SW, 364, AG1 -batteriekvivalenter och ersättare]()
2024/07/15
LR621- och SR621SW -knappbatterier är utbredda i kompakta elektroniska enheter som klockor, små leksaker, kalkylatorer och fjärrnycklar.Flera tillv... -
Grundläggande av op-amp kretsar
![Grundläggande av op-amp kretsar]()
2023/12/28
I den komplicerade elektronikvärlden leder en resa till dess mysterier alltid oss till ett kalejdoskop av kretskomponenter, både utsökta och komple... -
Jämförelse av NMO: er och PMOS -skillnader och applikationer
![Jämförelse av NMO: er och PMOS -skillnader och applikationer]()
2024/11/15
Att förstå skillnaderna mellan NMO: er och PMOS -transistorer är viktigt för att utforma effektiva kretsar.NMO: er (N-typ metall-oxid-halvledare) ... -
CR2450 vs CR2032 Jämförelse: allt du behöver veta
![CR2450 vs CR2032 Jämförelse: allt du behöver veta]()
2025/09/15
Knappbatterier som CR2450 och CR2032 driver många vardagliga elektronik, från klockor och fjärrkontroller till medicinska och industriella enheter....








Heta delar
- 74HC237D
- 6MBP35VDA120-50
- TAJV108K004RNJ
- EL7554IRE
- SSTUA32866BHLF
- SA53776242
- UC2709DW
- ADF4112BRUZ-REEL
- AT49LV1025-90JC
- TPS62237DRYT
- LD033A471FAB2A
- GRM2165C2A182JA01D
- CY8C21434-24LQXI
- C0603JB0J473M030BC
- IL3585
- TLC5954RTQR
- K4W2G0846P-HC15
- AP1605TSLA
- CS0805KKX7R7BB105
- LM4876MM/NOPB
- AB26S-R1
- CGA1A2X7R1C472M030BA
- 12065E273MAT2A
- TRS3221EIDBR
- ADS8881IDGSR
- PCM1752K
- C1608CH2A562J080AC
- GRM033R61C473ME84J
- SI3410DV-T1-E3
- NX8045GB-12M-STD-CSF-4
- BTS5589GX
- PIC16C72A-20/SO
- ACPF-7025-TR1
- 06031C471J4T4A
- AMD-8131BLC
- 1210ZC106MAT2A
- GCM1885C2A5R0CA16J
- T491A106M010ATAUTO
- NDY2405C
- VE-J6L-EY
- VE-J6J-MY
- XLR73234XD1300
- NS601680
- CMT1T-1RJ
- D761761A1ZVL
- KT1018TLD
- LE82P965SL9QX
- XC4VLX25-11FF676I
- CS400-16io1
- KSLCCBL1FB4G3A