- Svenska
-
EnglishDeutschItaliaFrançais한국의русскийSvenskaNederlandespañolPortuguêspolski繁体中文SuomiGaeilgeSlovenskáSlovenijaČeštinaMelayuMagyarországHrvatskaDanskromânescIndonesiaΕλλάδαБългарски езикGalegolietuviųMaoriRepublika e ShqipërisëالعربيةአማርኛAzərbaycanEesti VabariikEuskeraБеларусьLëtzebuergeschAyitiAfrikaansBosnaíslenskaCambodiaမြန်မာМонголулсМакедонскиmalaɡasʲພາສາລາວKurdîსაქართველოIsiXhosaفارسیisiZuluPilipinoසිංහලTürk diliTiếng ViệtहिंदीТоҷикӣاردوภาษาไทยO'zbekKongeriketবাংলা ভাষারChicheŵaSamoa日本語SesothoCрпскиKiswahiliУкраїнаनेपालीעִבְרִיתپښتوКыргыз тилиҚазақшаCatalàCorsaLatviešuHausaગુજરાતીಕನ್ನಡkannaḍaमराठी
Vad är en NPU och hur fungerar den i AI-enheter?
Katalog

Vad är en NPU?
En Neural Processing Unit (NPU) är en processor designad speciellt för AI och neurala nätverksarbetsbelastningar.Till skillnad från en CPU, som hanterar många olika typer av datoruppgifter, fokuserar en NPU huvudsakligen på operationer som används vid djupinlärning, bildigenkänning, talbearbetning, mönsterdetektering och AI-inferens.Eftersom hårdvaran är optimerad för dessa arbetsbelastningar kan den bearbeta AI-uppgifter mycket snabbare samtidigt som den använder mycket mindre ström.
Traditionella processorer som CPU:er och GPU:er kan fortfarande köra AI-modeller, men de är inte helt optimerade för neurala nätverksberäkningar.Under tung AI-bearbetning förbrukar de ofta mer elektricitet, genererar mer värme och spenderar ytterligare resurser på att hantera operationer som inte är relaterade till AI.När AI-funktioner fortsätter att expandera över smartphones, IoT-enheter, kameror, fordon, robotik och kantsystem, blir dessa begränsningar mer märkbara i verkliga applikationer.
En NPU förbättrar AI-exekveringen genom att organisera dess hårdvara runt det faktiska flödet av neurala nätverksberäkningar.Istället för att vänta genom långa sekventiella instruktionsköer, rör sig stora mängder data genom processorn samtidigt.Hårdvaran utför kontinuerligt operationer som matrismultiplikation, faltning, tensorberäkningar och parallell databehandling, som utgör grunden för moderna AI-modeller.Genom att minska onödig instruktionshantering och förkorta datarörelsevägar slutför processorn AI-arbetsbelastningar mer effektivt.
En stor skillnad mellan en NPU och en CPU är hur operationer bearbetas.En CPU utför vanligtvis instruktioner steg för steg samtidigt som den ständigt växlar mellan flera systemuppgifter.En NPU fungerar annorlunda genom att dela upp AI-arbetsbelastningar i många mindre operationer som körs samtidigt över flera datorenheter.Denna parallella struktur är mycket effektiv för arbetsbelastningar som bildanalys i realtid, röstigenkänning, videoförbättring, ansiktsdetektering och språkbehandling, där mycket stora mängder data måste bearbetas samtidigt.
Moderna NPU:er förbättrar också effektiviteten genom förenklade bearbetningskärnor, optimerade cachestrukturer och instruktionsuppsättningar som är utformade specifikt för AI-beräkning.Data rör sig genom processorn med färre fördröjningar, vilket hjälper till att minska både latens och energiförbrukning.Detta blir särskilt viktigt i bärbara enheter där batteritid och termisk kontroll direkt påverkar systemets övergripande prestanda.
Till skillnad från ASIC:er med fasta funktioner som endast stöder begränsade arbetsbelastningar, bibehåller NPU:er fortfarande en nivå av flexibilitet.Genom mjukvaruoptimering och programmerbart hårdvarubeteende kan de stödja olika AI-ramverk och neurala nätverksmodeller.Denna balans mellan specialiserad AI-acceleration och anpassningsförmåga tillåter NPU:er att fungera effektivt över många moderna intelligenta system som kräver snabb lokal AI-bearbetning.
Varför NPU:er är viktiga i moderna AI-system
En av de största fördelarna med en NPU är dess förmåga att bearbeta många beräkningar samtidigt.Neurala nätverk är starkt beroende av upprepade matematiska operationer över massiva datamängder, och NPU:n distribuerar dessa operationer över flera exekveringsenheter samtidigt istället för att bearbeta dem sekventiellt.Detta förbättrar avsevärt hastigheten för AI-inferens, bildbehandling och neurala nätverksberäkningar.
Den interna hårdvarustrukturen är också utformad specifikt för AI-arbetsbelastningar.Istället för att stödja ett brett utbud av generella datoruppgifter fokuserar processorn på de operationer som neurala nätverk använder oftast.Förenklade kärnor, optimerad minnesåtkomst och dedikerade AI-instruktionsvägar gör att data kan flyttas mer effektivt samtidigt som onödiga bearbetningskostnader minskar.
NPU:er förbättrar också prestandan genom effektiv datoranvändning med låg precision.Många AI-arbetsbelastningar kräver inte extremt hög numerisk precision för att ge korrekta resultat, så NPU:er använder ofta format som INT8 och FP16.Dessa format minskar minnesanvändning och beräkningskostnader, vilket gör att processorn kan slutföra fler operationer på kortare tid samtidigt som en stark slutledningsprestanda bibehålls.
Effekteffektivitet är en annan viktig anledning till att NPU:er blir viktiga i moderna enheter.Eftersom de flesta hårdvaruresurserna förblir fokuserade direkt på AI-bearbetning, slösas mycket mindre energi på orelaterade uppgifter.Jämfört med traditionella CPU:er och GPU:er kan NPU:er slutföra AI-arbetsbelastningar med mycket lägre effekt.Detta är särskilt värdefullt i smartphones, bärbar elektronik, smarta kameror, IoT-system och edge AI-hårdvara där batteritid och termisk kontroll är viktiga.
NPU:er minskar också minnesåtkomstoverhead genom att placera lagring och beräkning närmare varandra inom hårdvaruarkitekturen.I många traditionella processorer rör sig data ständigt fram och tillbaka mellan minne och datorenheter, vilket skapar förseningar och ökar strömförbrukningen.Kortare interna datavägar förbättrar genomströmningen och hjälper till att upprätthålla stabil prestanda under kontinuerliga AI-arbetsbelastningar.
När fler enheter fortsätter att integrera AI-funktioner på enheten blir NPU:er allt viktigare för att leverera snabba svarstider, effektiv lokal bearbetning och skalbar AI-prestanda i kompakta system.Uppgifter som objektdetektering i realtid, röstinteraktion, AI-bildförbättring, intelligent övervakning och lokal språkbehandling kan nu köras direkt på enheter utan att förlita sig mycket på molnberäkning.
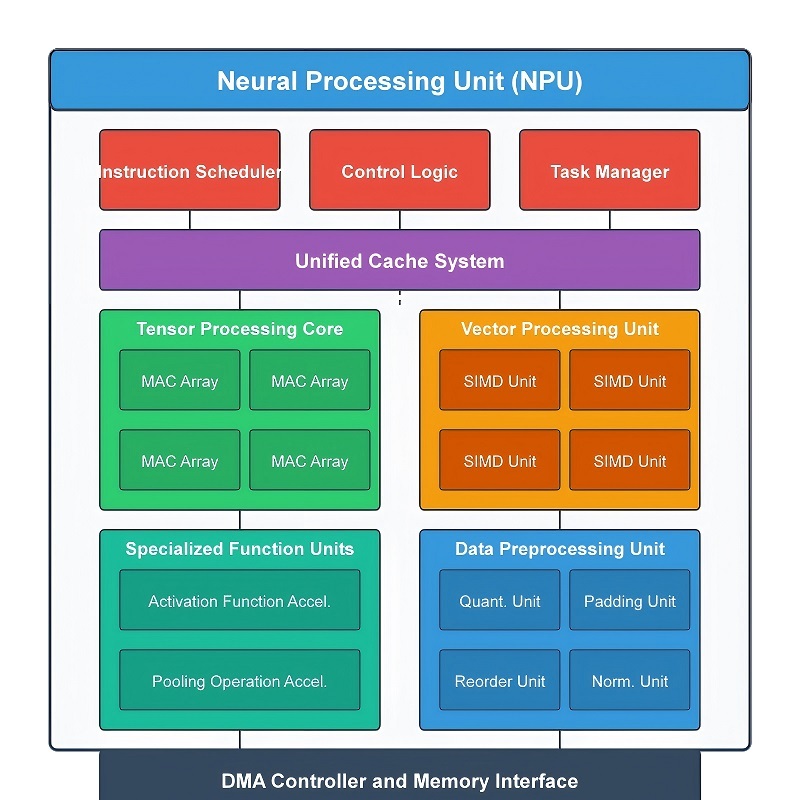
Kärnarkitektur och bearbetningsmoduler för en NPU
En NPU är byggd av flera specialiserade hårdvarumoduler som arbetar tillsammans för att bearbeta neurala nätverksarbetsbelastningar snabbt och effektivt.Istället för att skicka varje operation genom en allmän processor, delas arbetsbelastningen över dedikerade hårdvarublock som kontinuerligt behandlar data parallellt.Denna struktur förbättrar AI-inferenshastigheten, minskar onödiga datarörelser, sänker strömförbrukningen och hjälper till att upprätthålla effektiv minnesanvändning.
Under AI-bearbetning flödar data genom flera steg inuti processorn.Indata kommer först in i beräkningspipelinen, där storskaliga matematiska operationer utförs.Mellanresultat rör sig sedan genom aktiveringsbearbetning, tensoracceleration, bildrelaterade operationer och hårdvara för minnesoptimering innan den slutliga utmatningen produceras.Eftersom dessa moduler fungerar tillsammans i en koordinerad sekvens kan NPU:n bibehålla hög genomströmning även när man kör stora neurala nätverksmodeller.
Kärnberäknings- och aktiveringsmoduler
Den huvudsakliga datormotorn i en NPU är Multiply-Accumulate (MAC)-enheten.De flesta neurala nätverksarbetsbelastningar utför upprepade gånger multiplikation och addition över mycket stora datamängder, så den här hårdvaran hanterar majoriteten av AI-beräkningar under slutledning.När indata kommer in i ett neuralt nätverk multipliceras värden med lagrade viktvärden och adderas sedan för att generera nya utdata.Denna process upprepas kontinuerligt över många neurala nätverksskikt.
Moderna NPU:er innehåller ofta hundratals eller tusentals MAC-enheter som arbetar samtidigt.Istället för att beräkna en operation åt gången, fördelar hårdvaran arbetsbelastningar över många parallella exekveringsvägar.Stora partier av AI-data rör sig genom processorn tillsammans, vilket avsevärt förbättrar inferenshastigheten samtidigt som latensen hålls låg.I bildigenkänningssystem, till exempel, skannar MAC-enheter upprepade gånger grupper av pixlar och kombinerar filtervärden för att upptäcka kanter, texturer, former och mönster.I språkmodeller utför samma hårdvara storskaliga vektor- och matrisoperationer för att bearbeta tokens och relationer mellan ord.
Efter att dessa matematiska beräkningar är klara flyttas resultaten till modulen Aktiveringsfunktion.Neurala nätverk är beroende av icke-linjära aktiveringsfunktioner för att bearbeta komplexa relationer inom data.Utan aktiveringsbearbetning skulle nätverket bara utföra enkla linjära beräkningar och kunde inte hantera avancerade AI-uppgifter effektivt.
Denna modul exekverar funktioner som ReLU, Sigmoid och Tanh direkt i hårdvaran.Inkommande värden omvandlas snabbt enligt den valda aktiveringsregeln.ReLU, till exempel, tar bort negativa värden samtidigt som positiva utsignaler bevaras, vilket hjälper nätverket att fokusera på starkare funktionssignaler under slutledning.Eftersom aktiveringsbearbetning sker upprepade gånger över alla neurala nätverkslager, hjälper dedikerad accelerationshårdvara till att minska förseningar och förhindrar att de viktigaste beräkningsenheterna blir överbelastade.
Tensor och Spatial Data Processing Moduler
NPU:er inkluderar även specialiserad hårdvara för hantering av tensoroperationer och rumslig databehandling.Nästan alla moderna AI-modeller förlitar sig på tensorer, som är flerdimensionella datastrukturer som används för att organisera information över dimensioner som bredd, höjd, kanaler, funktionslager och partier.Stora mängder tensordata rör sig kontinuerligt mellan neurala nätverkslager under slutledning.
Tensoraccelerationsenheten bearbetar dessa tensorstrukturer direkt i hårdvaran.Operationer som tensormultiplikation, omformning, transformation och ackumulering utförs mycket snabbare än på processorer för allmänna ändamål.Denna dedikerade acceleration blir särskilt viktig i transformatorarkitekturer, datorseendesystem, stora språkmodeller och AI-applikationer i realtid som kräver mycket hög genomströmning.
Vid sidan av tensorbearbetning innehåller NPU:er också moduler utformade för 2D och rumsliga dataoperationer som vanligtvis används i bild- och videoarbetsbelastningar.Computer vision-system ändrar hela tiden storlek, omorganiserar, filtrerar och flyttar stora mängder pixeldata innan en djupare AI-analys påbörjas.Att hantera dessa uppgifter separat förbättrar effektiviteten och minskar trycket på huvuddatormotorn.
Under bildbearbetning hanterar hårdvaran operationer som nedsampling, rörelsekartor, bildkopiering, storleksändring, beskärning och rumslig dataöverföring.Till exempel kan högupplöst video som tagits med en kamera först ändras i storlek och omorganiseras innan den går in i det neurala nätverkets pipeline.Detta minskar beräkningsbelastningen samtidigt som viktig visuell information som behövs för objektdetektering och scenanalys bevaras.
Moduler för minnesoptimering och datakomprimering
Moderna AI-modeller kräver stora mängder minne för att lagra neurala nätverksvikter, tensorer och mellanliggande data.Att ständigt överföra denna information mellan minne och datorhårdvara ökar bandbreddsanvändning, latens och strömförbrukning.För att minska denna omkostnad inkluderar NPU:er dedikerade datakomprimerings- och dekompressionsmoduler.
Innan data lagras i minnet komprimeras upprepade mönster och viktvärden till mindre format.Under exekvering återställs den komprimerade informationen snabbt och skickas direkt in i datapipeline.Detta minskar minnestrafiken och gör att mer AI-data kan finnas kvar i lokalt höghastighetsminne närmare processorn.
Avancerade komprimeringsmetoder kan ofta reducera modellstorleken flera gånger samtidigt som man bibehåller nästan samma slutledningsnoggrannhet.Detta blir särskilt viktigt i smartphones, inbyggda system, smarta kameror, bärbar elektronik och andra avancerade AI-enheter där minneskapacitet och energieffektivitet är begränsad.
Hur dessa moduler fungerar tillsammans
Prestandan hos en NPU är inte beroende av ett enda hårdvarublock.Dess effektivitet kommer från hur alla bearbetningsmoduler fungerar tillsammans som en koordinerad pipeline.
En typisk AI-arbetsbelastning börjar med storskalig matematisk beräkning inuti MAC-enheterna.Mellanliggande resultat passerar sedan genom aktiveringsbearbetning för att introducera olinjärt beteende i det neurala nätverket.Tensoraccelerationshårdvara organiserar och bearbetar kontinuerligt flerdimensionell data genom hela pipelinen, medan rumsliga bearbetningsmoduler hanterar bild- och videorelaterade operationer.Samtidigt minskar kompressionshårdvaran minnesöverföringskostnader i bakgrunden.
Eftersom dessa operationer körs samtidigt över dedikerade hårdvaruvägar kan NPU:n bearbeta stora AI-arbetsbelastningar med hög genomströmning, lägre latens och mycket bättre energieffektivitet än traditionella processorer.
NPU:er i smartphones och mobil AI
Moderna smartphones hanterar ett enormt antal operationer varje sekund.En telefon kan låsa upp med ansiktsigenkänning, öppna kameran, bearbeta foton, översätta tal och köra AI-assisterade applikationer nästan omedelbart.För att stödja denna prestandanivå inuti tunna mobila enheter med begränsad batterikapacitet, förlitar sig smartphones på mycket integrerade System-on-Chip (SoC)-arkitekturer.
Inuti SoC arbetar flera processorer tillsammans, och varje processor är optimerad för olika arbetsbelastning.CPU:n hanterar systemkontroll, applikationer och allmänna datoruppgifter.GPU:n hanterar grafikåtergivning, spel och visuell bearbetning.NPU (Neural Processing Unit) fokuserar specifikt på AI-beräkning.
Istället för att dirigera neurala nätverksarbetsbelastningar genom CPU eller GPU, riktar smartphones många AI-uppgifter till NPU:n, där hårdvaran är optimerad för snabb parallell AI-bearbetning.Denna separation förbättrar effektiviteten eftersom varje processor hanterar den typ av arbetsbelastning den är designad för.Som ett resultat kan smartphones utföra avancerade AI-operationer med snabbare svarstider, lägre latens och bättre energieffektivitet.
Hur NPU:er förändrade Smartphone AI
Innan mobila NPU:er blev vanliga, berodde många smarttelefons AI-funktioner starkt på molnberäkning.Uppgifter som röstigenkänning, språköversättning, bildförbättring och intelligenta assistenter krävde ofta att data laddades upp till fjärrservrar för bearbetning innan resultaten returnerades till enheten.Detta skapade förseningar, ökade nätverkstrafik och väckte integritetsproblem.
Introduktionen av dedikerade mobila NPU:er förändrade detta arbetsflöde avsevärt.AI-modeller kunde nu köras direkt på själva smarttelefonen, vilket gör att många operationer kan utföras lokalt i realtid istället för att vara helt beroende av externa servrar.
Denna förändring gav flera stora fördelar:
• Lägre latens eftersom data inte längre behöver konstant molnkommunikation
• Snabbare AI-svarstider under realtidsoperationer
• Bättre integritetsskydd eftersom känslig data kan finnas kvar på enheten
• Lägre strömförbrukning genom hårdvara optimerad specifikt för AI-arbetsbelastningar
• Stabilare AI-prestanda även med svaga eller otillgängliga internetanslutningar
När mobila NPU:er blev kraftfullare började smartphones köra avancerade AI-funktioner kontinuerligt i bakgrunden utan märkbara förseningar under daglig användning.
Hur smartphones använder NPU:er i verkliga operationer
AI-fotografering och bildbehandling
En av de mest synliga användningsområdena för mobila NPU:er är AI-fotografering.Moderna smartphonekameror förlitar sig inte längre bara på bildsensorer och traditionella bildbehandlingsalgoritmer.AI-modeller analyserar nu bilddata kontinuerligt medan kameran är igång.
När kameraappen öppnas börjar smarttelefonen omedelbart bearbeta den inkommande bildströmmen ruta för ruta.NPU:n analyserar ljusförhållanden, objektgränser, ansiktsdetaljer, färger, texturer och rörelsemönster i realtid.Baserat på denna analys justerar systemet exponering, vitbalans, HDR-inställningar, skärpa och kontrast nästan omedelbart innan bilden tas.
Vid fotografering i svagt ljus kombinerar NPU:n flera bildramar tillsammans för att förbättra ljusstyrkan och samtidigt minska visuellt brus.Under porträttfotografering separerar processorn förgrundsmotiv från bakgrundsområden och applicerar djupeffekter mer exakt runt kanter som hår, glasögon och klädeskonturer.
Scenigenkänning beror också mycket på NPU:n.Processorn jämför bildmönster med utbildade AI-modeller för att identifiera miljöer som mat, landskap, husdjur, dokument, solnedgångar eller nattscener.När kameran har identifierats justerar den automatiskt inställningarna för att optimera bildkvaliteten.
Eftersom dessa beräkningar sker direkt på smarttelefonen känns AI-fotografering nästan omedelbar även om stora mängder neurala nätverksberäkningar sker kontinuerligt i bakgrunden.
Röstigenkänning och AI-assistenter
Röstassistenter och talrelaterade funktioner är också mycket beroende av lokal AI-acceleration.När en användare pratar med smarttelefonen fångar mikrofonen råa ljudsignaler som måste rengöras, separeras och omvandlas till igenkännbara talmönster.
NPU:n bearbetar kontinuerligt ljudströmmen genom att identifiera fonem, filtrera bakgrundsljud och matcha ljudmönster mot taligenkänningsmodeller.Lokal AI-bearbetning gör att väckningsord och vanliga röstkommandon kan upptäckas nästan omedelbart utan att ständigt överföra ljudinspelningar till molnservrar.
Detta förbättrar lyhördheten för uppgifter som:
• Röstkommandon
• Taltranskription i realtid
• Språköversättning
• Interaktion med AI-assistent
• AI-anropsförbättring
• Brusreducering under videosamtal
Eftersom mycket av bearbetningen sker direkt på enheten förblir röstinteraktionen smidigare även under instabila nätverksförhållanden.
AI-spel och systemoptimering i realtid
Moderna smartphones använder också NPU:er för speloptimering och intelligent systemhantering.Under spelandet övervakar AI-modeller efterfrågan på ramåtergivning, arbetsbelastningsbeteende, termiska förhållanden, beröringsmönster och batterianvändning i realtid.
Systemet kan dynamiskt justera GPU-arbetsbelastningar, optimera krafttilldelning, stabilisera bildhastigheter och minska överhettning under långa spelsessioner.Vissa smartphones använder också tekniker för AI-uppskalning och rörelseprediktion för att förbättra visuell jämnhet samtidigt som de behåller lägre energiförbrukning.
Utanför spel hjälper NPU till att optimera bakgrundsapplikationer, batterihantering, förutsägande användarinteraktioner och uppgiftsschemaläggning baserat på enhetens användningsmönster.
Utveckling av mobila NPU:er
Utvecklingen av mobila NPU: er accelererade snabbt när AI-arbetsbelastningar för smartphones blev mer avancerade och beräkningskrävande.
|
Period |
Mobil NPU-utveckling |
|
2017 — Tidiga kommersiella mobila NPU:er |
Huawei introducerade en av de första kommersiella smartphones
NPU:er genom Kirin 970-processorn.Detta markerade en stor förändring mot
storskalig on-device AI acceleration inuti konsumentsmartphones.I stället för
förlitar sig huvudsakligen på CPU:er och GPU:er för AI-uppgifter, inklusive smartphones nu
dedikerad AI-hårdvara direkt inuti SoC-arkitekturen. |
|
2018 — Utbyggnad av On-Device AI |
Apple introducerade Neural Engine inuti A12 Bionic
chip, förbättra AI-bearbetning för ansiktsigenkänning, beräkning
fotografering och intelligenta mobila funktioner.On-device AI blev en major
fokus på flaggskeppsutveckling av smartphones. |
|
2019–2020 — Industriomfattande AI-integration |
Stora chiptillverkare inklusive Qualcomm, Samsung och
MediaTek började integrera dedikerade AI-acceleratorer i flaggskeppsmobilen
processorer.AI-prestanda började bli en viktig konkurrensfaktor i
smartphone hårdvara design. |
|
2021–2023 — AI-bearbetning blir ett centralt riktmärke |
Smartphonetillverkare jämförde NPU allt oftare
prestanda tillsammans med CPU- och GPU-prestanda.NPU:er blev centrala för
beräkningsfotografering, röst-AI, videoförbättring, batterioptimering,
och intelligenta systemfunktioner. |
|
2024–2025 — Stora AI-modeller som körs på smartphones |
Moderna mobila NPU:er fick tillräckligt med processorkraft för att
stödja större AI-modeller direkt på smartphones och edge-enheter.Mer AI
arbetsbelastningar kunde nu köras lokalt utan att vara starkt beroende av molnet
infrastruktur, vilket förbättrar både lyhördhet och integritet. |
Jämförelse av nuvarande mainstream mobila NPU:er
Moderna flaggskeppssmarttelefonprocessorer inkluderar nu mycket avancerade NPU-arkitekturer optimerade för realtids-AI-inferens, hög genomströmning och förbättrad energieffektivitet.
|
Mobil processor |
NPU-funktioner |
|
Apple A17 Pro |
Inkluderar en 26-kärnig neuralmotor designad för snabb
AI-bearbetning på enheten.Arkitekturen förbättrar AI-fotografering, röst
igenkänning och intelligenta systemfunktioner i realtid på alla Apple-enheter. |
|
Qualcomm Snapdragon 8 Gen 3 |
Använder en uppgraderad Hexagon AI-processor optimerad för
generativ AI, neural nätverksacceleration, avancerad bildbehandling och
effektiva mobila AI-arbetsbelastningar. |
|
MediaTek Dimensity 9300 |
Inkluderar en sjätte generationens APU (AI Processing Unit) med
stora förbättringar av AI-inferenshastighet och AI-bearbetning i realtid
kapacitet för smartphones och edge-enheter. |
|
Samsung Exynos 2400 |
Har en nästa generations mobil NPU fokuserad på snabbare
AI-behandling på enheten för beräkningsfotografering, intelligent system
operationer och avancerade mobila AI-applikationer. |
NPU vs GPU vs CPU: Viktiga skillnader i AI-bearbetning
Både GPU:er och NPU:er är designade för att behandla stora mängder data parallellt, men de byggdes för väldigt olika ändamål.En GPU utvecklades ursprungligen för grafikrendering, medan en NPU skapades specifikt för neurala nätverksberäkningar och AI-inferens.
På grund av denna skillnad i designmål hanterar de två processorerna AI-arbetsbelastningar på väldigt olika sätt.GPU:er kan köra AI-modeller effektivt, särskilt i storskaliga träningssystem, men de bär fortfarande mycket av komplexiteten hos en grafikprocessor.NPU:er förenklar många av dessa operationer genom att fokusera nästan helt på AI-relaterade beräkningar.
Hur GPU:er hanterar AI-arbetsbelastningar
En GPU (Graphics Processing Unit) designades först för att bearbeta grafikdata som texturer, ljuseffekter, geometriska transformationer och bildåtergivning.För att stödja dessa arbetsbelastningar innehåller GPU:er tusentals parallella bearbetningskärnor som kan hantera många operationer samtidigt.
När AI-arbetsbelastningen ökade började GPU:er användas för utbildning och slutledning av neurala nätverk eftersom hårdvaran redan stödde storskalig parallell bearbetning.Matrisoperationer som används i djupinlärning skulle kunna distribueras över många GPU-kärnor, vilket kraftigt ökar bearbetningshastigheten jämfört med CPU:er.
GPU:er är dock fortfarande starkt beroende av processorn för övergripande koordination.Under AI-bearbetning hanterar CPU:n vanligtvis:
• Schemaläggning av uppgifter
• Minnestilldelning
• Dataförflyttning
• Instruktionskontroll
• Samordning på systemnivå
En typisk AI-arbetsbelastning på en GPU involverar kontinuerlig kommunikation mellan CPU, GPU-minne och datorenheter.Data överförs upprepade gånger mellan lagringsbuffertar, cachesystem och exekveringskärnor innan resultaten returneras för nästa steg i bearbetningen.
Detta arbetsflöde är kraftfullt, men det ökar också:
• Strömförbrukning
• Användning av minnesbandbredd
• Dataöverföringskostnader
• Systemkomplexitet
• Värmeutveckling
I högpresterande servrar kan dessa begränsningar hanteras med stora kylsystem och hög tillgång till elektrisk ström.I mobila enheter eller edge-enheter blir dock samma tillvägagångssätt mycket mindre effektivt.
Hur NPU:er bearbetar AI mer effektivt
En NPU (Neural Processing Unit) är byggd specifikt kring den faktiska strukturen av neurala nätverksberäkningar.Istället för att stödja ett brett utbud av grafik eller allmänna funktioner fokuserar hårdvaran nästan helt på AI-inferens och tensorbehandling.
Under körning av AI flödar neurala nätverksdata genom dedikerade hårdvaruvägar optimerade för operationer som:
• Matrismultiplikation
• Konvolution
• Tensoracceleration
• Funktionsextraktion
• Parallella neurala nätverksberäkningar
Till skillnad från GPU:er använder NPU: er mycket optimerade AI-instruktionsuppsättningar som är designade direkt för djupinlärning.Detta ändrar hur arbetsbelastningar exekveras på hårdvarunivå.
Till exempel kan en GPU kräva många lager av instruktionsschemaläggning och minneshantering för att slutföra en neural nätverksuppgift.En NPU kan ofta utföra samma operation med mycket färre instruktioner eftersom hårdvarupipelinen redan matchar strukturen för AI-beräkning.
Detta minskar onödiga bearbetningssteg och förbättrar:
• Slutledningshastighet
• Energieffektivitet
• Respons i realtid
• Genomströmning för AI-arbetsbelastningar
Resultatet är snabbare lokal AI-bearbetning med lägre hårdvarukostnader.
Skillnader i datarörelse
En av de största skillnaderna mellan GPU:er och NPU:er är hur data rör sig genom processorn under beräkning.
GPU-dataflöde
I ett GPU-baserat system färdas data ständigt mellan:
• Minnesbuffertar
• Cachelager
• Bearbetning av kärnor
• Externa minnessystem
Stora AI-modeller kräver enorma mängder tensordata för att kunna röra sig kontinuerligt över hårdvaran.Varje överföring förbrukar bandbredd och ström samtidigt som det inför förseningar.
Under exekvering av neurala nätverk laddas vikter och mellanutgångar upprepade gånger från minnet, bearbetas och skrivs sedan tillbaka igen för nästa steg i beräkningen.När modellstorleken ökar blir minnestrafiken en stor flaskhals.
NPU-dataflöde
NPU:er minskar denna omkostnad genom att placera lagring och beräkning närmare varandra inuti hårdvaruarkitekturen.Många NPU-designer använder bearbetningsstrukturer inspirerade av neurala nätverksdataflöden, där beräkning och vikthantering förblir tätt sammankopplade under hela körningen.
Istället för att upprepade gånger flytta stora mängder data över långa hårdvaruvägar, håller processorn mer information nära exekveringsenheterna.Mellanliggande resultat kan flyttas direkt mellan specialiserade moduler med färre minnesåtkomstoperationer.
Denna kortare och mer effektiva dataväg förbättrar:
• Genomströmning
• Latens
• Bandbreddseffektivitet
• Strömförbrukning
Förbättringen blir särskilt viktig under kontinuerlig AI-inferens på mobila och avancerade enheter.
Effekteffektivitet och termisk prestanda
Effekteffektivitet är en av de starkaste fördelarna med NPU:er.
Högpresterande GPU:er förbrukar stora mängder elektricitet eftersom de innehåller enorma parallella datorresurser utformade för grafikrendering och storskalig beräkning.Under tung arbetsbelastning genererar GPU:er också betydande värme och kräver ofta avancerade kylsystem som värmerör, ångkammare eller aktiva fläktar.
I stationära arbetsstationer och AI-servrar är dessa krav hanterbara eftersom utrymme och kraft är mindre begränsade.Smartphones, bärbara enheter, smarta kameror och IoT-system fungerar under mycket olika förhållanden.
Mobila enheter måste ha:
• Lång batteritid
• Stabila temperaturnivåer
• Kompakt hårdvarustorlek
• Tyst drift
• Kontinuerlig respons i realtid
NPU:er är designade kring dessa begränsningar.Eftersom hårdvaran fokuserar specifikt på AI-inferens, slösas färre resurser på orelaterade operationer.Processorn kan utföra neurala nätverksuppgifter med mycket lägre energianvändning jämfört med GPU:er.
Detta gör NPU:er mycket lämpliga för:
• Smartphones
• Bärbar elektronik
• Smarta kameror
• Bärbara enheter
• Autonoma sensorer
• Edge AI-system
• Batteridriven IoT-hårdvara
Olika roller för GPU:er och NPU:er
Även om NPU:er ger stora fördelar för AI-inferens, är GPU:er fortfarande extremt viktiga i många datormiljöer.
Där GPU:er presterar bäst
GPU:er är mycket effektiva för:
• Grafikåtergivning
• Vetenskaplig simulering
• 3D-modellering
• Videobehandling
• Storskalig AI-utbildning
• Datacenterberäkning
• Högpresterande datorarbete
Att träna stora neurala nätverk kräver enorm beräkningsflexibilitet och flyttalsbearbetningsförmåga, vilket GPU:er hanterar mycket bra.
Där NPU:er presterar bäst
NPU:er är optimerade främst för:
• AI-inferens i realtid
• Lokal AI-bearbetning
• Lågeffekt intelligenta system
• Edge AI-arbetsbelastningar
• Mobil AI-acceleration
• Kontinuerliga AI-uppgifter i bakgrunden
Istället för att träna massiva modeller fokuserar NPU:er på att köra tränade modeller effektivt inuti kompakta enheter.
Detta gör att smartphones, kameror, fordon, robotsystem och smart elektronik kan utföra AI-operationer lokalt med snabba svarstider och lägre beroende av molnservrar.
Varför NPU:er blir viktigare
När AI-funktioner blir en del av vardagliga enheter fortsätter efterfrågan på effektiv lokal AI-bearbetning att öka.Användare förväntar sig nu att smartphones och smarta enheter ska utföra uppgifter som:
• Språköversättning i realtid
• Förbättring av AI-fotografering
• Röstinteraktion
• Ansiktsigenkänning
• Intelligent videoanalys
• Objektdetektering
• Personliga rekommendationer
Dessa arbetsbelastningar kräver snabb slutledning med låg latens och kontrollerad energianvändning.
GPU:er är fortfarande viktiga för högpresterande datorer och AI-träningsinfrastruktur, men NPU:er håller på att bli den föredragna lösningen för AI-acceleration på enheten och kantintelligens i realtid.
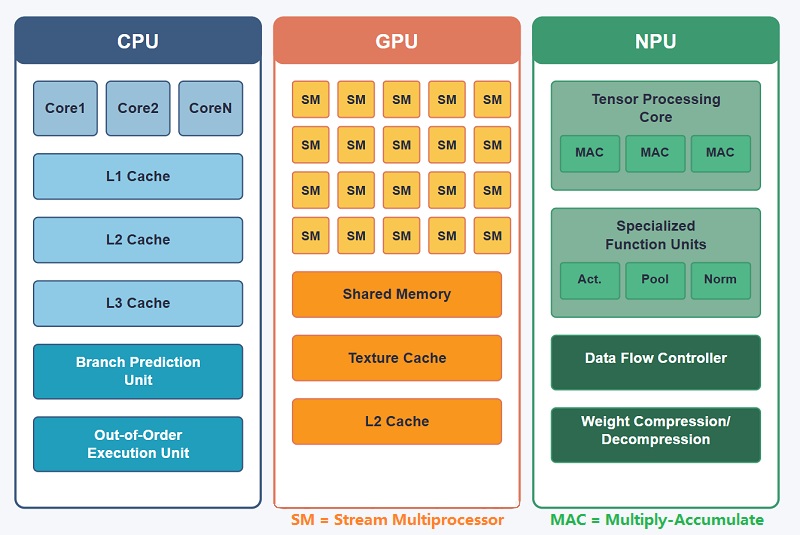
Specialiserade bearbetningsenheter inom modern datoranvändning
Moderna datorsystem använder många olika typer av processorer eftersom ingen enskild arkitektur effektivt kan hantera varje arbetsbelastning.Vissa processorer fokuserar på systemkontroll, vissa är specialiserade på grafikrendering, medan andra är optimerade för AI-acceleration, nätverk, vetenskaplig beräkning eller inbyggd kontroll.
Inuti moderna smartphones, servrar, industriella system, robotplattformar, fordon och avancerade AI-enheter arbetar ofta flera bearbetningsenheter tillsammans samtidigt.Varje processor hanterar den typ av arbetsbelastning som den är speciellt designad för, vilket förbättrar prestanda, energieffektivitet och lyhördhet i realtid i moderna datormiljöer.
CPU: Central Processing Unit
En CPU (Central Processing Unit) är huvudstyrenheten i de flesta datorsystem.Den hanterar operativsystem, applikationer, minneskoordinering, uppgiftsschemaläggning och kommunikation mellan hårdvarukomponenter.
CPU:er är mycket flexibla och kan hantera många olika arbetsbelastningar på ett tillförlitligt sätt, vilket gör dem viktiga i datorer, smartphones, servrar och inbyggda system.De är dock mindre effektiva för storskaliga parallella AI-arbetsbelastningar jämfört med mer specialiserade processorer.
GPU: Graphics Processing Unit
En GPU (Graphics Processing Unit) är optimerad för storskalig parallell bearbetning.Arkitekturen innehåller många exekveringskärnor som kan hantera tusentals operationer samtidigt.
GPU:er utvecklades ursprungligen för grafikrendering, men de används nu i stor utsträckning för AI-träning, vetenskaplig simulering, videobearbetning och högpresterande datorer på grund av deras starka parallella beräkningsförmåga.
NPU: Neural Processing Unit
En NPU (Neural Processing Unit) är designad specifikt för neurala nätverksacceleration och AI-inferens.Hårdvaran fokuserar på tensorberäkning, matrismultiplikation, faltningsoperationer och AI-bearbetning med låg effekt.
NPU:er används ofta i smartphones, smarta kameror, edge AI-system, robotik och intelligenta enheter där snabb lokal AI-bearbetning och energieffektivitet är viktigt.
TPU: Tensor Processing Unit
En TPU (Tensor Processing Unit) är optimerad för tensorbaserade AI-arbetsbelastningar och storskalig acceleration av djupinlärning.Dessa processorer är främst designade för moln AI-infrastruktur och maskininlärningsmiljöer för datacenter.
TPU:er är mycket effektiva för:
• Träning för djupinlärning
• Stora AI-modeller
• Tensorberäkning
• Cloud AI-tjänster
• AI-acceleration med hög genomströmning
FPGA: Omkonfigurerbar hårdvarubearbetning
En FPGA (Field-Programmable Gate Array) använder programmerbara logiska block som kan konfigureras för specifika uppgifter efter tillverkning.Till skillnad från fasta processorarkitekturer tillåter FPGA att själva hårdvarufunktionen anpassas.
FPGA används ofta i:
• Kommunikationssystem
• Bilelektronik
• Industriell automation
• Flyg- och rymdsystem
• Edge computing
• Medicinsk utrustning
DPU: Databehandlingsenhet
En DPU (Data Processing Unit) är optimerad för datacentrerade arbetsbelastningar i molninfrastruktur och nätverkssystem.DPU:er hjälper till att minska CPU-arbetsbelastningen genom att påskynda datarörelser, lagringsoperationer, kryptering och nätverkstrafikhantering.
Dessa processorer används vanligtvis i:
• Datacenter
• Cloud computing
• Höghastighetsnätverk
• Lagringsacceleration
• Serverinfrastruktur
VPU: Vision Processing Unit
En VPU (Vision Processing Unit) är specialiserad på datorseende och bildbaserad AI-behandling.VPU:er påskyndar arbetsbelastningar som ansiktsigenkänning, objektdetektering, rörelsespårning och videoanalys.
VPU:er finns vanligtvis i:
• Smarta kameror
• Övervakningssystem
• Robotik
• Autonoma fordon
• AR/VR-system
• Edge AI vision-enheter
IPU: Intelligence Processing Unit
En IPU (Intelligence Processing Unit) är designad för mycket parallella arbetsbelastningar för AI och maskininlärning.Arkitekturen fokuserar på att förbättra dataflödeseffektiviteten under storskalig exekvering av neurala nätverk.
IPU:er används för:
• Maskininlärningsacceleration
• Mönsterigenkänning
• AI slutledning
• Parallell tensorbehandling
• Avancerad AI-forskning
BPU: Brain Processing Unit
En BPU (Brain Processing Unit) är optimerad för inbyggda AI och edge intelligence-system.Dessa processorer fokuserar på snabb lokal AI-inferens med lägre strömförbrukning.
BPU:er används vanligtvis i:
• Smarta avkänningssystem
• Robotik
• Edge AI-hårdvara
• Rörelsedetekteringssystem
• Autonoma plattformar
HPU: Holographic Processing Unit
En HPU (Holographic Processing Unit) är designad för holografisk beräkning, mixed reality och rumsliga analyssystem.
HPUs hjälpprocess:
• Miljökartläggning
• Rörelsespårning
• Sensorfusion
• Rumslig interaktion i realtid
• AR/VR-miljöer
MPU och MCU: Embedded Control Processing
MPU:er (Microprocessor Units) och MCU:er (Microcontroller Units) används ofta i inbyggda system och lågeffektelektronik.
MPU:er används vanligtvis i inbyggda datorsystem som kräver styrning på operativsystemnivå, medan MCU:er integrerar processorkärnor, minne och in-/utgångskontroll i ett kompakt chip för dedikerade lågeffektuppgifter.
Dessa processorer finns vanligtvis i:
• IoT-enheter
• Industriregulatorer
• Bilelektronik
• Hushållsapparater
• Bärbara inbyggda system
APU: Accelerated Processing Unit
En APU (Accelerated Processing Unit) kombinerar CPU- och GPU-funktionalitet i ett enda processorpaket.Denna integrering förbättrar energieffektiviteten, minskar maskinvarustorleken och tillåter dator- och grafikarbetsbelastningar att dela systemresurser mer effektivt.
APU:er används ofta i:
• Bärbara datorer
• Mini-datorer
• Spelsystem på nybörjarnivå
• Multimediaenheter
• Bärbara datorplattformar
Varför moderna system använder flera specialiserade processorer
Moderna datorsystem förlitar sig sällan på en enda processorarkitektur.Istället kombinerar enheter flera specialiserade processorer eftersom olika arbetsbelastningar kräver olika bearbetningsmetoder.
Till exempel kan ett modernt system använda:
• CPU:er för systemkontroll
• GPU:er för grafik och parallell beräkning
• NPU:er för AI-inferens
• VPU:er för datorseende
• DPU:er för nätverk och dataförflyttning
• MCU:er för inbyggda kontrolluppgifter
Genom att fördela arbetsbelastningar över dedikerad hårdvara, uppnår moderna system bättre prestanda, lägre latens, förbättrad energieffektivitet och effektivare realtidsbearbetning över AI, grafik, nätverk och inbyggda datormiljöer.
Praktiska tillämpningar av NPU:er

NPU:er används nu över ett brett utbud av intelligenta system eftersom moderna AI-arbetsbelastningar i allt högre grad kräver snabb lokal bearbetning istället för konstant molnkommunikation.Genom att köra neurala nätverksslutningar direkt på lokal hårdvara kan enheter svara snabbare, minska bandbreddsanvändningen, förbättra integriteten och upprätthålla stabil realtidsprestanda även under begränsade nätverksförhållanden.
När AI-modeller blev mindre och mer effektiva expanderade NPU:er långt bortom smartphones och forskningssystem till industriell automation, robotik, sjukvårdsenheter, nätverksinfrastruktur, autonoma maskiner, smarta kameror, IoT-plattformar och edge AI-system.Deras förmåga att behandla AI-arbetsbelastningar kontinuerligt med lägre strömförbrukning och lägre latens gör dem mycket värdefulla i moderna realtidsdatormiljöer.
NPU:er i smartphones och konsumentenheter
Smartphones är fortfarande ett av de vanligaste exemplen på NPU-integration.Moderna mobila enheter använder NPU:er för AI-fotografering, röstassistenter, språkbehandling, speloptimering, bildförbättring och intelligent batterihantering.
Smartphonekameror använder till exempel NPU:er för att analysera ljusförhållanden, känna igen scener, förbättra fotografering i svagt ljus och tillämpa bildförbättring i realtid direkt på enheten.Röstassistenter förlitar sig också på lokal AI-acceleration för taligenkänning, brusdämpning, transkription och naturlig språkbehandling.
Eftersom dessa AI-operationer körs lokalt på smarttelefonen upplever användarna snabbare svarstider, lägre latens, förbättrad integritet och minskat beroende av molnbearbetning.
NPU:er i Edge AI-system
Edge AI-system behandlar data lokalt nära källan istället för att kontinuerligt överföra information till avlägsna molnservrar.NPU:er är särskilt viktiga i dessa miljöer eftersom de ger snabb AI-inferens samtidigt som de bibehåller låg strömförbrukning och effektiv drift i realtid.
Edge AI-plattformar använder vanligtvis NPU:er för:
• Objektdetektering i realtid
• Lokal bildbehandling
• Sensoranalys
• Prediktiv övervakning
• Intelligent automation
• Videoanalys
Genom att bearbeta AI-arbetsbelastningar lokalt kan edge-system reagera mycket snabbare samtidigt som bandbreddskraven och beroendet av molninfrastruktur minskar.
NPU:er inom industriell AI och automation
Industriella system använder i allt högre grad NPU:er för realtidsanalys av AI över tillverkning, inspektion, förutsägande underhåll och automatiserade kontrollsystem.
Fabriker använder ofta kameror, sensorer och robotsystem som kontinuerligt genererar driftsdata.NPU:er hjälper till att bearbeta denna information lokalt för att identifiera utrustningsfel, upptäcka tillverkningsfel, övervaka maskinens beteende och optimera produktionseffektiviteten med minimal fördröjning.
Industriella AI-tillämpningar inkluderar vanligtvis:
• Automatiserade inspektionssystem
• Defektdetektering
• Förutsägande underhåll
• Robotstyrning
• Sensorfusion
• Intelligent produktionsövervakning
Eftersom dessa arbetsbelastningar kräver kontinuerlig drift och snabba svarstider, blir lokal AI-acceleration med låg latens mycket viktig.
NPU:er inom robotik och autonoma system
Robotsystem är starkt beroende av AI-inferens i realtid för att interagera säkert och effektivt med föränderliga miljöer.Robotar bearbetar kontinuerligt kamerainmatning, sensordata, miljökartläggning, djupinformation och rörelsespårning under drift.
NPU: er accelererar dessa arbetsbelastningar genom att hantera neurala nätverksberäkningar lokalt med lägre latens och snabbare svarstider.Detta gör att robotar kan reagera snabbare under navigering, hinderdetektering, objektspårning och autonom rörelse.
Autonoma system som självkörande plattformar är också mycket beroende av NPU:er för:
• Fildetektering
• Fotgängarigenkänning
• Trafikanalys
• Sensorbearbetning
• Miljökartläggning
• Navigeringsbeslut i realtid
Eftersom autonoma system måste reagera omedelbart på förändrade omgivningar, blir lokal AI-bearbetning viktig för säker och stabil drift.
NPU:er inom sjukvård och medicinska system
Sjukvårdssystem använder i allt större utsträckning NPU:er för AI-assisterad medicinsk analys, patientövervakning och bärbara sjukvårdsenheter.
Medicinsk AI-arbetsbelastning kräver ofta kontinuerlig analys av biologiska signaler, bilddata och övervakningssystem i realtid.NPU: er hjälper till att påskynda dessa uppgifter samtidigt som de minskar förseningar under övervakningsoperationer.
Vanliga vårdapplikationer inkluderar:
• Medicinsk bildanalys
• Patientövervakningssystem
• Bärbara diagnostiska enheter
• Pulsanalys
• AI-assisterad diagnostik
• Kontinuerlig hälsoövervakning
Lokal AI-acceleration hjälper också till att förbättra integriteten eftersom känslig medicinsk data kan finnas kvar inuti enheten istället för att ständigt överföras till externa servrar.
NPU:er i smarta hem och IoT-enheter
IoT-enheter och smarta hemsystem fungerar ofta med begränsad datorkraft och strikta energibegränsningar, vilket gör NPU:er mycket värdefulla för effektiv lokal AI-bearbetning.
Enheter som smarta kameror, smarta högtalare, hemassistenter, säkerhetssystem och miljösensorer använder NPU:er för att analysera data direkt på enheten utan att förlita sig mycket på molninfrastruktur.
Vanliga IoT AI-arbetsbelastningar inkluderar:
• Ansiktsigenkänning
• Rörelsedetektering
• Mänsklig närvarodetektering
• Röstinteraktion
• Objektigenkänning
• Smarta övervakningssystem
Lokal AI-bearbetning minskar bandbreddsanvändningen, förbättrar svarshastigheten och gör att IoT-system kan förbli aktiva under långa perioder med lägre strömförbrukning.
NPU:er i nätverks- och kommunikationssystem
Moderna nätverkssystem använder i allt högre grad NPU:er för intelligent kommunikationshantering och trafikanalys i realtid.
Kommunikationsinfrastruktur bearbetar kontinuerligt stora mängder nätverksdata, anslutningsaktivitet och trafikbeteende.NPU: er hjälper till att accelerera AI-arbetsbelastningar relaterade till bandbreddsallokering, anomalidetektering, signaloptimering och nätverkstrafikhantering.
Dessa system använder vanligtvis NPU:er för:
• Intelligent trafikprioritering
• Signaloptimering
• Detektering av nätverksavvikelser
• Kommunikationsanalys
• Bandbreddshantering i realtid
Genom att bearbeta dessa arbetsbelastningar lokalt och effektivt kan nätverkssystem reagera snabbare på förändrade kommunikationsförhållanden.
Varför NPU:er blir viktigare
Moderna AI-system kräver i allt högre grad snabb lokal slutledning, respons i realtid, lägre latens och effektiv strömförbrukning i många olika miljöer.Cloud-only AI-bearbetning är ofta för långsam, bandbreddskrävande eller opraktisk för system som måste reagera omedelbart.
NPU:er löser detta problem genom att accelerera neurala nätverksarbetsbelastningar direkt på lokal hårdvara.När AI expanderar över smartphones, industriell automation, robotik, sjukvårdssystem, IoT-enheter, autonoma maskiner och avancerade datorplattformar, håller NPU:er på att bli en av kärnteknologierna bakom moderna intelligenta system.
Framtida trender för NPU:er
NPU-tekniken går in i en period av snabb utveckling när AI-arbetsbelastningen fortsätter att expandera över smartphones, industrisystem, robotik, autonoma maskiner, edge AI-plattformar, molninfrastruktur och intelligenta konsumentenheter.Moderna AI-modeller blir större, mer komplexa och mer krävande när det gäller bearbetningshastighet, minnesbandbredd, termisk effektivitet och strömförbrukning.
Tidig NPU-utveckling fokuserade främst på att öka den råa AI-prestandan.Framtida utveckling kommer att gå bortom enkel prestandaskalning och fokusera mer på intelligent arbetsbelastningsallokering, effektivt dataflöde, adaptivt hårdvarubeteende, lågeffekt slutledning och djupare integration med bredare AI-ekosystem.När AI blir djupare integrerad i vardagliga enheter och industriella miljöer, förväntas NPU:er bli en av kärnteknologierna bakom nästa generations intelligenta datorsystem.
Smartare AI-arkitekturer
Framtida NPU-arkitekturer kommer att bli mer anpassningsbara, specialiserade och tätt integrerade med andra processorer i moderna datorsystem.Istället för att fungera som isolerade hårdvarublock kommer NPU:er att arbeta närmare med CPU:er, GPU:er, DSP:er och andra acceleratorer genom delade minnessystem och koordinerad arbetsbelastningshantering.
Under drift kan arbetsbelastningar automatiskt skifta mellan processorer beroende på termiska förhållanden, effektgränser, modellkomplexitet och efterfrågan på realtidsbehandling.Sekventiella kontrolluppgifter kan finnas kvar på CPU:n, grafikbelastning på GPU:n, medan neurala nätverksslutledningar flyttas dynamiskt till NPU:n.
Framtida arkitekturer kan också omorganisera hårdvaruresurser dynamiskt under exekvering.AI-arbetsbelastningar fokuserade på bildigenkänning kan prioritera tensor- och faltningshårdvara, medan språkbearbetningsuppgifter kan allokera mer resurser till uppmärksamhetsmekanismer och minnesbandbredd.
Samtidigt kommer framtida NPU i allt högre grad att inkludera hårdvarublock optimerade för specifika AI-arbetsbelastningar som:
• Transformator uppmärksamhetsbehandling
• Rörledningar för synslutning
• Taligenkänning
• Rekommendationssystem
• Generativa AI-arbetsbelastningar
• Multimodal AI-bearbetning
Denna kombination av dynamiskt hårdvarubeteende och specialiserad AI-acceleration kommer att förbättra genomströmningen, minska onödig beräkning och öka den totala effektiviteten under komplexa AI-arbetsbelastningar.
Lågeffekt och effektiv AI-beräkning
Effekteffektivitet kommer att bli en av de viktigaste prioriteringarna i framtida NPU-utveckling, särskilt när AI-arbetsbelastningar expanderar till smartphones, bärbar elektronik, industriella sensorer och avancerade AI-enheter.
Framtida NPU:er kommer att fortsätta utöka stödet för lågprecisionsformat som INT4, INT8, FP16, BF16 och ultralågbitars AI-beräkning.Istället för att använda samma numeriska precision över alla neurala nätverkslager, kan framtida system dynamiskt justera precisionsnivåer beroende på arbetsbelastningskänslighet.
Detta tillvägagångssätt minskar:
• Minnesöverföringskostnader
• Förvaringskrav
• Strömförbrukning
• Beräkningslatens
samtidigt som den totala genomströmningen ökar.
Gles beräkningsacceleration kommer också att bli allt viktigare.Många neurala nätverk innehåller inaktiva eller lågviktiga regioner som bidrar lite till den slutliga utdatakvaliteten.Framtida NPU:er kan automatiskt upptäcka och kringgå dessa regioner för att undvika att slösa energi på onödiga beräkningar.
Ett annat stort utvecklingsområde är in-memory computing.Istället för att kontinuerligt överföra neurala nätverksdata mellan minne och exekveringshårdvara, kan framtida arkitekturer utföra vissa tensorberäkningar direkt inuti minnesstrukturer.Nya teknologier som ReRAM, MRAM, fasförändringsminne och avancerade 3D-staplade arkitekturer kan avsevärt minska minnesflaskhalsar samtidigt som de förbättrar bandbreddseffektiviteten och sänker energiförbrukningen.
Hjärninspirerad och adaptiv AI-hårdvara
Neuromorphic computing går gradvis från experimentell forskning mot praktiskt utplacering.Dessa arkitekturer är inspirerade av biologiska neurala system och bearbetar information annorlunda än traditionella klockdrivna processorer.
Istället för att utföra operationer kontinuerligt med fasta tidsintervall använder neuromorfa system ofta händelsedrivna bearbetningsmetoder som liknar spikande neurala nätverk.Beräkning sker främst när meningsfulla signaler dyker upp, vilket kraftigt minskar onödig aktivitet inuti processorn.
Framtida NPU:er kan inkludera specialiserat stöd för:
• Spikande neurala nätverk
• Händelsedriven slutledning
• Adaptiv neural inlärning
• Kontinuerlig lokal optimering
Detta tillvägagångssätt kan avsevärt förbättra energieffektiviteten för robotik, bärbara enheter, miljöavkänningssystem och autonoma AI-plattformar som kräver kontinuerlig drift med låg effekt.
Framtida AI-hårdvara kan också anpassa beteendet dynamiskt baserat på användarinteraktionsmönster och miljöförhållanden, vilket gör att enheter kan förbättra personalisering och lokal inlärning utan att förlita sig mycket på träningssystem på molnet.
Edge AI och lokala stora modeller
Framtida NPU:er kommer att dramatiskt utöka den lokala AI-kapaciteten vid kanten.Istället för att vara starkt beroende av molnservrar kommer fler enheter att behandla AI-arbetsbelastningar direkt på lokal hårdvara med lägre latens, snabbare svarstider och bättre integritetsskydd.
Edge AI-system kommer i allt högre grad att stödja:
• Kontinuerlig lokal slutledning
• Lättviktsutbildning på enheten
• Distribuerat AI-samarbete
• Intelligent övervakning i realtid
• Avkänningssystem med ultralåg effekt
Samtidigt går stora språkmodeller och avancerade generativa AI-system gradvis mot lokal exekvering på smartphones, bärbara datorer, robotplattformar och edge-hårdvara.
Framtida NPU:er kommer att ge acceleration för arbetsbelastningar som:
• Konversations-AI
• Översättning i realtid
• Intelligent sammanfattning
• Offline AI-assistenter
• Kontextmedvetna resonemang
• Generativ AI på enheten
Multimodal AI kommer också att bli mycket vanligare.Framtida system kommer att behandla text, video, ljud, sensordata, miljökartläggning och rumslig interaktion samtidigt i realtid.Detta kommer att bli särskilt viktigt inom robotik, autonoma system, AR/VR-plattformar, industriell automation och intelligenta edge-enheter.
Halvledare och hårdvaruinnovation
Framsteg inom halvledartillverkning kommer att fortsätta driva på stora förbättringar av NPU-kapaciteten.Mindre processnoder tillåter fler transistorer att passa in i kompakta kretsar samtidigt som växlingseffekten minskar och beräkningstätheten förbättras.
Framtida NPU-utveckling kommer i allt högre grad att förlita sig på:
• Chiplet-arkitekturer
• 3D-stapling
• Avancerad förpackningsteknik
• Sammankopplingssystem med hög bandbredd
• Modulära AI-acceleratordesigner
Istället för att bygga en mycket stor processormatris kan framtida system kombinera flera specialiserade chipmoduler i tätt integrerade paket.Separata chiplets kan hantera tensoracceleration, minneshantering, kommunikationskontroll eller AI-schemaläggning oberoende med bibehållen extremt hög intern bandbredd.
Forskare utforskar också avancerade halvledarmaterial som grafen, kolnanorör och sammansatta halvledare som ytterligare kan förbättra växlingshastighet, termisk effektivitet och energiprestanda i framtida AI-hårdvara.
AI-säkerhet och ekosystemutveckling
När fler AI-arbetsbelastningar flyttas direkt till lokal hårdvara, kommer AI-säkerhet och ekosystemutveckling att bli allt viktigare.
Framtida NPU:er kan inkludera dedikerad hårdvaruacceleration för:
• Federerat lärande
• Krypterad AI-exekvering
• Säker modellförvaring
• Differentiell integritet
• Skyddade slutledningsledningar
Detta blir särskilt viktigt i sjukvårdssystem, industriell infrastruktur, autonoma system, finansiella plattformar och personliga AI-assistenter där känslig information måste förbli skyddad under lokal AI-bearbetning.
Framtida NPU-ekosystem kommer också att bli mer standardiserade och utvecklarvänliga.AI-kompilatorer, felsökningsmiljöer, optimeringsramverk och distributionsverktyg kommer att fortsätta att förbättras i takt med att hårdvaruarkitekturerna blir mer specialiserade.
Framtida AI-programvarusystem kan automatiskt:
• Optimera tensorexekveringsvägar
• Ordna om minnesallokering
• Justera precisionen dynamiskt
• Generera hårdvaruspecifik accelerationskod
• Förbättra plattformsoberoende kompatibilitet
Standardiserade gränssnitt och bredare ekosystemkompatibilitet kommer att bidra till att minska fragmenteringen mellan hårdvaruleverantörer samtidigt som portabiliteten, skalbarheten och utvecklingseffektiviteten förbättras inom AI-branschen.
Slutsats
NPU:er blir viktiga i modern datoranvändning eftersom de tillåter AI-uppgifter att köras lokalt, snabbt och effektivt utan att vara mycket beroende av molnbearbetning.Deras optimerade arkitektur minskar latens, strömanvändning, minnesrörelse och värmegenerering, vilket gör dem värdefulla i smartphones, robotteknik, sjukvårdsenheter, industriell automation, smarta hem, autonoma system och avancerade AI-plattformar.När AI-modeller blir större och mer komplexa kommer framtida NPU:er att fortsätta att förbättras genom smartare arkitekturer, lågprecisionsberäkning, bearbetning i minnet, stöd för lokala stora modeller, avancerad halvledardesign och starkare AI-säkerhetsfunktioner.
Vanliga frågor [FAQ]
1. Varför är NPU:er mer effektiva än CPU:er för neurala nätverksarbetsbelastningar?
NPU:er är mer effektiva eftersom deras hårdvara är designad specifikt för AI-beräkning istället för allmän bearbetning.En CPU hanterar många olika systemuppgifter sekventiellt, medan en NPU huvudsakligen fokuserar på tensoroperationer, matrismultiplikation, faltning och parallell neurala nätverksbehandling.Detta gör att NPU:er kan slutföra AI-inferens snabbare samtidigt som de använder mindre ström och genererar mindre värme.
2. Hur förbättrar parallell bearbetning NPU-prestanda under AI-inferens?
NPU:er delar upp AI-arbetsbelastningar i många mindre operationer som körs samtidigt över flera datorenheter.Istället för att vänta på att en instruktion ska avslutas innan en annan påbörjas, rör sig stora mängder neurala nätverksdata parallellt genom processorn.Detta förbättrar avsevärt genomströmningen och minskar latensen under arbetsbelastningar som bildigenkänning, talbearbetning och objektdetektering i realtid.
3. Varför är lågprecisionsberäkning viktig i moderna NPU:er?
Många AI-modeller kräver inte extremt hög numerisk precision för att ge korrekta resultat.NPU:er använder format som INT8 och FP16 för att minska minnesanvändning och beräkningsoverhead.Bearbetning med lägre precision gör att fler operationer kan slutföras på kortare tid samtidigt som energieffektiviteten förbättras och en stark AI-inferensprestanda bibehålls.
4. Hur minskar NPU:er flaskhalsar vid minnesöverföring jämfört med GPU:er?
NPU:er placerar minne och beräkningshårdvara närmare varandra inuti processorarkitekturen.Istället för att upprepade gånger överföra stora mängder tensordata mellan externt minne och bearbetningskärnor kvarstår många mellanliggande operationer nära exekveringsenheterna.Detta förkortar datavägar, minskar bandbreddsanvändningen, minskar latensen och förbättrar den totala energieffektiviteten.
5. Varför blir NPU:er användbara i smartphones och avancerade AI-enheter?
Moderna enheter kräver snabb lokal AI-bearbetning med låg strömförbrukning och minimal latens.NPU:er tillåter smartphones och edge-system att utföra AI-uppgifter som ansiktsigenkänning, AI-fotografering, röstinteraktion och objektdetektering direkt på enheten utan att vara mycket beroende av molnservrar.Detta förbättrar lyhördhet, integritet och batterieffektivitet.
6. Hur bidrar MAC-enheter till NPU-acceleration?
Multiply-Accumulate (MAC)-enheter hanterar de upprepade multiplikations- och additionsoperationerna som används i neurala nätverk.Moderna NPU:er innehåller hundratals eller tusentals MAC-enheter som arbetar samtidigt, vilket gör att stora AI-arbetsbelastningar kan behandlas mycket snabbare än på traditionella sekventiella processorer.
7. Varför använder moderna AI-system både GPU:er och NPU:er istället för att förlita sig på en processortyp?
GPU:er och NPU:er är optimerade för olika arbetsbelastningar.GPU:er utmärker sig vid storskalig AI-träning, grafikrendering och högpresterande parallellberäkning, medan NPU:er är optimerade för lågeffekts AI-inferens och lokal bearbetning i realtid.Genom att använda båda processorerna tillsammans kan systemen balansera flexibilitet, prestanda och energieffektivitet.
8. Hur förbättrar NPU:er AI-bearbetning i realtid i robotik och autonoma system?
Robotik och autonoma system bearbetar kontinuerligt kamerainmatning, miljökartläggning, sensordata och rörelseanalys.NPU: er accelererar dessa arbetsbelastningar lokalt med låg latens, vilket gör att system kan reagera snabbt under navigering, hinderdetektering, fotgängarigenkänning och beslutsfattande i realtid.
9. Varför blir AI på enheten viktigare för framtida NPU-utveckling?
AI på enheten minskar beroendet av cloud computing genom att tillåta AI-modeller att köras direkt på lokal hårdvara.Detta förbättrar integriteten, minskar användningen av nätverksbandbredd och möjliggör snabbare realtidssvar.Framtida NPU:er förväntas stödja större lokala AI-modeller, multimodal AI-bearbetning och avancerade generativa AI-arbetsbelastningar direkt inuti konsument- och industriella enheter.
10. Hur kan framtida NPU-arkitekturer förändra AI-hårdvarueffektiviteten?
Framtida NPU:er kommer sannolikt att använda smartare arbetsbelastningsallokering, sparsam beräkning, bearbetning i minnet, chiplet-arkitekturer och adaptiv precisionskontroll för att förbättra effektiviteten.Dessa teknologier syftar till att minska onödig beräkning, lägre energiförbrukning och öka genomströmningen samtidigt som de stöder större och mer avancerade AI-modeller över edge-enheter, robotik, industriella system och intelligent konsumentelektronik.
Besläktad blogg
-
Hur många nollor i en miljon, miljarder biljoner biljoner biljetter?
![Hur många nollor i en miljon, miljarder biljoner biljoner biljetter?]()
2024/07/29
Miljoner representerar 106, en lätt greppbar siffra jämfört med vardagliga artiklar eller årslöner. Miljarder, motsvarande 109, börjar sträcka ... -
IRLZ44N MOSFET -datablad, krets, motsvarande, pinout
![IRLZ44N MOSFET -datablad, krets, motsvarande, pinout]()
2024/08/28
IRLZ44N är en allmänt använt N-kanals Power MOSFET.Det är känt för sina utmärkta växlingsfunktioner och passar mycket för många applikatione... -
Batteritemperaturen för låg, laddningen stannade.Hur fixar jag det?
![Batteritemperaturen för låg, laddningen stannade.Hur fixar jag det?]()
2024/10/6
Problem med avladdning av batteriladdning av mobiltelefoner är vanliga men kan hanteras effektivt.Temperaturen spelar en stor roll i batterieffektivi... -
BC547 Transistor Comprehensive Guide
![BC547 Transistor Comprehensive Guide]()
2024/07/4
BC547 -transistorn används vanligtvis i en mängd elektroniska applikationer, allt från grundläggande signalförstärkare till komplexa oscillatork... -
Omfattande guide till SCR (kiselstyrd likriktare)
![Omfattande guide till SCR (kiselstyrd likriktare)]()
2024/04/22
Kiselstyrda likriktare (SCR) eller tyristorer spelar en viktig roll i kraftelektroniktekniken på grund av deras prestanda och tillförlitlighet.Den h... -
LR621, SR621SW, 364, AG1 -batteriekvivalenter och ersättare
![LR621, SR621SW, 364, AG1 -batteriekvivalenter och ersättare]()
2024/07/15
LR621- och SR621SW -knappbatterier är utbredda i kompakta elektroniska enheter som klockor, små leksaker, kalkylatorer och fjärrnycklar.Flera tillv... -
Grundläggande av op-amp kretsar
![Grundläggande av op-amp kretsar]()
2023/12/28
I den komplicerade elektronikvärlden leder en resa till dess mysterier alltid oss till ett kalejdoskop av kretskomponenter, både utsökta och komple... -
Jämförelse av NMO: er och PMOS -skillnader och applikationer
![Jämförelse av NMO: er och PMOS -skillnader och applikationer]()
2024/11/15
Att förstå skillnaderna mellan NMO: er och PMOS -transistorer är viktigt för att utforma effektiva kretsar.NMO: er (N-typ metall-oxid-halvledare) ... -
En komplett guide till multiplexerare och deras roll i digitala system
![En komplett guide till multiplexerare och deras roll i digitala system]()
2025/09/20
Multiplexerare är komponenter i digitala system, utformade för att kanalisera flera insignaler till en enda utgångslinje med binära logik och styr... -
Vad betyder STD, AGM och Gel på en batteriladdare
![Vad betyder STD, AGM och Gel på en batteriladdare]()
2024/07/10
Traditionella bly-syra batteriladdare är kända för sin enkelhet och tillförlitlighet.De har tjänat sitt syfte effektivt i flera år, till stor de...








Heta delar
- KSZ9031RNXIC-TR
- CCP2B80DTTE
- GRM1556R1H5R4DZ01D
- ICL7107CPLZ
- H5MS2G22MFR-EBM
- HY825DC256160CE-5C
- AP2141FMG-7
- RN4020-V/RM123
- AD5300BRMZ
- KMPC8245LZU266D
- MSP4450G-QI-C13
- TNETE2201B
- LD125C105KAB4A
- XMC1100T016F0016AAXUMA1
- LTC6254CMS#PBF
- SC1443PPCRK1VD
- GRM1555C1H6R0CA01J
- BCM5702WKFB
- PF38F4060M0Y0YEA
- AP2141DMPG-13
- TPS2320IDR
- MC79L05ACD
- EP4CE6E22C6N
- LCMXO3LF-6900E-6MG256C
- LMC6035ITLX/NOPB
- LFE3-35EA-6FN484I
- CC1206KRX7R0BB473
- BTS5235-2L
- LC87F2832AUFL64TBM-E
- CSD17571Q2
- SI4702DY-T1-E3
- VND5E025AY
- AD9554BCPZ
- ADUM1200BRZ
- 12105C105JAT2A
- BM29F040-90AC
- TWL1200YFFR
- VI-JND-CW
- VE-224-EX
- CY7C1350-100AC
- ICS9DB102BGLFT
- MC34164DM-5
- PC48F4400POVB00
- SPDA26353A-QL241
- LC272H3BT-03C-E
- RE200GE
- CY7C1313TV18
- CY7B994V-5ACT
- SSD2830TQL9
- G7SA-2A2B DC24